|
||||
|
|
III. Интерактивные инструменты обработки текстаIII.1. Поиск OCR ошибок в текстеЭти инструменты предназначены для ручного поиска и самостоятельной корректировки слов. Они часто бывают полезны после OCR. Многие ошибки в тексте можно исправить с помощью автоматического Корректора Текста. Но он не все корректирует «до конца». Например, при корректировании разрыва абзацем дефиса и переноса слов, в зависимости от выбора режима корректировки, часто остаются не обработанными либо слова с дефисами, либо слова с переносами, т. к. есть случаи, которые невозможно программно отследить, и только человек способен правильно решить, что это – слово с дефисом или же слово с разорванным переносом. Для такого случая и подобных и созданы ручные инструменты коррекции текста: 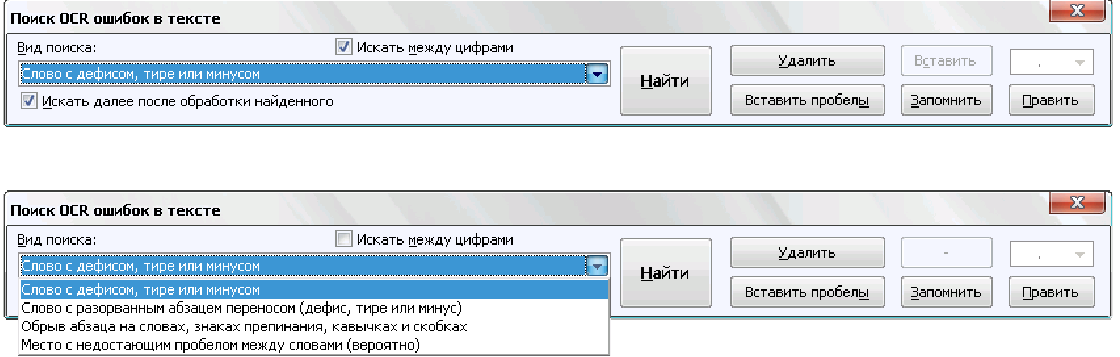 Диалог «Поиск OCR ошибок в тексте» выполнен, как немодальный, т. е. с него легко «перейти» на найденного им слово для ручной коррекции, не закрывая при этом этот диалог. Но эта возможность может понадобиться крайне редко, т. к. предусмотрена кнопка «Удалить» («Вставить», «Обработать» – название и назначение меняется в зависимости от вида поиска), нажатие на которой вносит необходимые изменения в найденный текст. Диалог «запоминает» свое местоположение на экране, и при следующем его вызове он отобразится в том месте, где вы его закрыли в прошлый раз. Это удобно. Его можно расположить над меню и панелями инструментов OOo (сделано по умолчанию), и он не будет «мешать» видеть текст во время поиска. Поиск ручным корректором и внесение изменений осуществляется везде – в тексте, в таблицах, в текстовых врезках и в сносках. Поиск начинается от позиции курсора в документе и идет «по-кругу». Корректировка найденного текста по нажатию кнопки (справа от кнопки «Найти») работает «интеллектуально», т. к., если после того, как вы нашли что-то (этот текст выделяется), а потом перешли курсором в другое место, или выделили случайно другое место в тексте, и нажали на корректирующую кнопку, то, если нет выделения – ничего не будет откорректировано. А если выделение есть, то в нем будет проведен поиск OCR-ошибки, согласно выбранного вида поиска, и в случае обнаружения, произойдет коррекция текста. Конечно, все случаи «защиты от глупости» не предусмотришь… Опция «Искать далее после обработки найденного»: Если она выключена, то после того, как инструмент нашел ошибку OCR, и вы ее обработали с помощью кнопок обработки, текстовый курсор остается на найденном, и чтобы найти новую ошибку OCR, надо нажать кнопку «Найти». И так – до конца книги. Если же опция «Искать далее после обработки найденного» включена, то после обработки найденной ошибки автоматически происходит переход на новую ошибку в тексте! Это очень удобно! Поиск слов с дефисами, тире или минусом Инструмент позволяем искать в тексте слова с дефисами, например: «кое-что», «серый- серый», «по-своему», «ты-ли», «ангел-хранитель» и т. д. Польза этого инструмента – после работы Корректора Текста в автоматическом режиме можно найти слова, где из разорванных переносов был удален только знак абзаца, а дефис (или «минус») – оставлен. Если и он должен быть удален, то теперь это можно сделать вручную. Например, нашли: «замеча-тельно». Здесь перенос – явно лишний. Удаляем… С другой стороны, можно найти другие слова с тире, дефисом или минусом и заменить эти символы «на ваш вкус». Обрабатывается и неразрывный дефис. Опция «Искать между цифрами» нужна для возможности включить/отключить поиск минуса, тире и дефиса между цифрами. Очень часто в книгах встречаются такие конструкции: 12-34, 1972-2010 и т. д. (В христианской литературе – это ссылка на стихи Библии, например, Мф. 5:1-8. В исторических книгах – это указание на отрезок времени. И т. д.). В таких книгах, как правило, минус, тире или дефис между цифрами – это не ошибка OCR, а норма. При вычитке инструмент часто находит такие цифры с дефисами, что утомляет. Чтобы пропустить эти «правильные» цифры и не тратить на них время нужно отключить опцию «Искать между цифрами». Для поиска используется шаблон регулярных выражений: При включенной опции «Искать между цифрами»: \‹[: alnum: ]+[-" amp; chr(8209) amp; chr(8211) amp; chr(8212) amp; "][: alnum: ]+ При выключенной опции «Искать между цифрами»: \‹[: alpha: ]+[-" amp; chr(8209) amp; chr(8211) amp; chr(8212) amp; "][: alpha: ]+ Кнопка Вставить пробелы активна только для этого режима. При нажатии на ней, если найдено слово, содержащие дефис, минус или тире, то слева и справа от этого минуса, дефиса или тире ставятся пробелы. Это полезно для «слипшихся» слов и тире… Например, найдено слово «Ты – нет!». После нажатия кнопки Вставить пробелы, получаем «Ты – нет!», как и должно было быть. В этом режиме поиска предусмотрена возможность Запоминать найденное «хорошее» дефисное слово (Кнопка Запомнить), и Редактировать файл списка этих дефисных слов (Кнопка Править). Слова «запоминаются» в. txt-файл words_defis_list.txt, который создается в папке config пакета OOo. Для Unix – подобных систем – это папка /home/XXX/.openoffice.org3/user/config/OOoFBTools. Для Windows – это папка C: \Documents and Settings\XXX\Application Data\OpenOffice.org3\user\config\OOoFBTools, где XXX – ваш логин (имя пользователя). Как это работает? Когда найдено очередное слово с минусом, неразрывным дефисом, дефисом или тире, то, чтобы инструмент не останавливался в следующий раз на этом же слове, его можно «Запомнить». И теперь оно будет «благополучно» пропускаться при поиске. Предусмотрены защиты от «глупости»: слово не будет «запоминаться», если: – нет выделения в тексте; – выделено слово, не содержащее ни минуса, ни тире, ни дефиса, ни неразрывного дефиса; – случайно пользователем выделено несколько абзацев. Во всех этих случаях будет выдано соответствующее предупреждение. При Правке файла списка дефисных слов (нажатие кнопки Править) файл words_defis_list.txt будет запущен в ассоциированном с расширением. txt в вашей системе текстовом редакторе. Лучше ассоциировать. txt с редактором, который поддерживает Unicode и корректно «видит» перевод строк (абзацы). В Windows notepad.exe для этого не подходит. В Windows я пользуюсь Notepad++.exe. Поиск слов, в которых абзац разорвал перенос (дефис, тире или минус) Этот инструмент позволяет искать в документе разрыва дефисов и слов. Например: «давным-¶», «из-¶», «пересмотре-¶». Если после знака переноса стоит один или пробелов, то такие слова тоже находятся. Например: «давным- ¶», «из- ¶», «пересмотре- ¶» Обрабатывается и неразрывный дефис. Для поиска используется шаблон регулярных выражений: "\‹[: alnum: ]+[-" amp; chr(8209) amp; chr(8211) amp; chr(8212) amp; "]$|\‹[: alnum: ]+[-" amp; chr(8209) amp; chr(8211) amp; chr(8212) amp; "][: space: ]$" Поиск обрыва абзаца на словах, знаках препинания, кавычках и скобках Например, есть текст: Это пример того, как можно «найт軶 разрыв предложения на кавычках,¶ запятой, (тексте в скобках) ¶ что часто бывает нужно после OCR. Еще пример: Здесь – разрыв после пробела и тире -¶ А здесь – разрыв после 2-х пробелов, минуса и пробела – ¶ Для поиска используется шаблон регулярных выражений: "\‹[: alnum: ]+$|\‹[: alnum: ]+[)}\],»”\"":;]$|\‹[: alnum: ]+[)}\]\.,»”\"":;]+[)}\],»”\"":;]$|[: space: ]+ [-" amp; chr(8209) amp; chr(8211) amp; chr(8212) amp; "]$" amp; "|[: space: ]+[-" amp; chr(8209) amp; chr(8211) amp; chr(8212) amp; "][: space: ]+$" Т.е. отлавливаются не только разрывы на запятых, скобках и словах, но и на минусе, тире и дефисах, слева от которых стоит 1 или более пробелов, а справа – ни один или множество пробелов (частая ошибка OCR). Кнопка «Обработать» позволяем удалить разрыв предложения и вставить пробел. В этом варианте поиска активируется выпадающий список знака пунктуации, который можно выбрать, и при нажатии кнопки «Вставить» он будет вставлен «на свое место». Кнопка «Склеить» позволяет просто удалить разрыв, не вставляя пробел. Это полезно, т. к. часто при OCR (особенно в FR10) слово оказывается разорванным не как, например «по-¶шел», а «по¶шел». Поэтому «Склейка» склеивает разорванное слово. Поиск вероятного недостающего пробела между словами Ищет слова с вероятным отсутствием пробела между ними по знакам препинания, закрывающим скобкам. Опция «Искать между цифрами» нужна для возможности включить/отключить поиск недостающего пробела между цифрами. Очень часто в книгах встречаются такие конструкции: 12,34, 1972:2010 и т. д. (В христианской литературе – это ссылка на стихи Библии, например, Ин. 3:16. В математических книгах и книгах по программированию – это указание на числовые диапазоны, просто дробные числа. И т. д.). В таких книгах, как правило, отсутствие пробела между цифрами – это не ошибка OCR, а норма. При вычитке инструмент часто находит такие цифры "без пробела", что утомляет. Чтобы пропустить эти «правильные» цифры и не тратить на них время нужно отключить опцию «Искать между цифрами». Для поиска используется шаблон регулярных выражений: При включенной опции «Искать между цифрами»: \‹[: alnum: ]+[)}\]({\[,!?…»”\"":;«“][: alpha: ]+|\‹[: alpha: ]+[: digit: ]+|\‹[: digit: ]+[: alpha: ]+ При выключенной опции «Искать между цифрами»: \‹[: alpha: ]+[)}\]({\[,!?…»”\"":;«“][: alpha: ]+|\‹[: alpha: ]+[: digit: ]+|\‹[: digit: ]+[: alpha: ]+ При корректировании в этом режиме поиска программа сама определяет, где поставить пробел – слева или справа от найденного знака препинания, скобки или кавычек. III.2. Обработка выделенных абзацев (обрыв абзаца или строки) 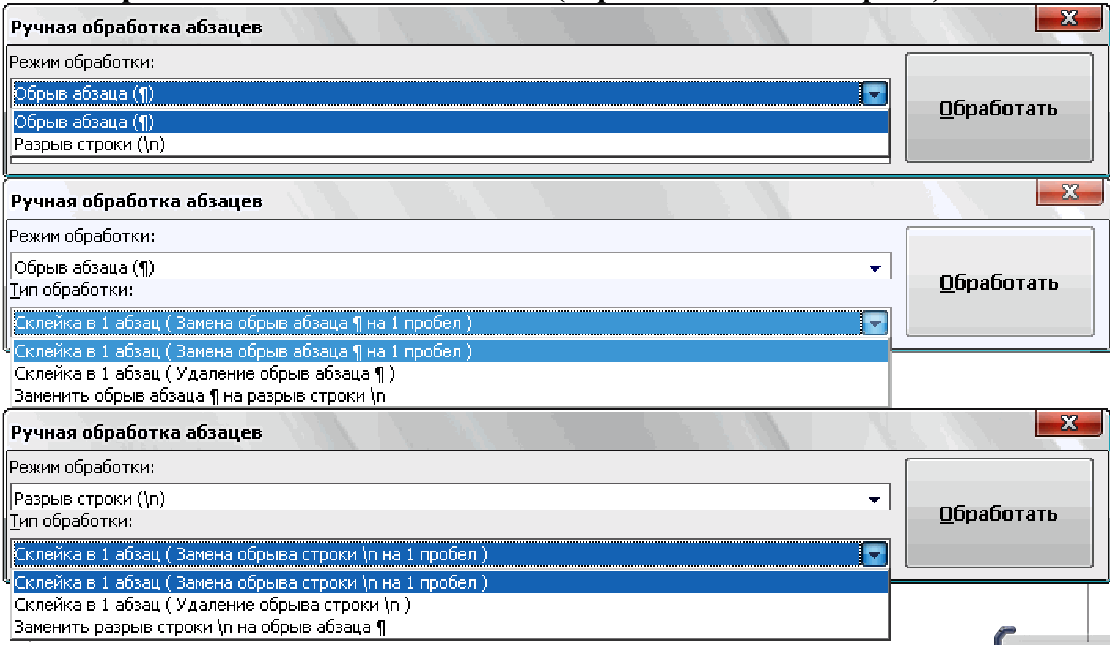 Часто требуется не автоматическая обработка текста, а ручная некоторых фрагментов. Данный набор инструментов может работать как с одним выделенным фрагментом текста, так и с несколькими выделенными областями текста. Если нет ни одного выделенного фрагмента, то инструменты могут обработать весь документ (появляется соответствующее окно с вопросом). Выделять можно только Текст. Инструменты не работают с Врезками и Таблицами. Например, есть текст с обрывом абзацев (показаны скрытые символы):  В этом тексте есть и обрыв абзаца, и обрыв строки (тэг ‹BR› в html-файлах). Делаем следующее: 1. Выделяем те строки, где есть разрыв строки:  Запускаем инструменты Ручная обработка абзацев, выбираем Режим обработки: Разрыв строки (\n) и Тип обработки: Склейка в 1 абзац (Замена обрыва строки \n на 1 пробел). После нажатия Обработать, получили следующее:  Теперь выделяем все строки, разорванные абзацев, причем в каждое выделение должны попасть только те строки, которые должны составить один целый абзац:  Для инструмента Ручная обработка абзацев, выбираем Режим обработки: Обрыв абзаца (¶) и Тип обработки: Склейка в 1 абзац (Замена обрыва строки \n на 1 пробел). После нажатия Обработать, получили следующее:  Что и требовалось. Разорванные строки 2-х абзаце мы склеили, каждые в свой абзац. Разобраться с остальными Типами обработки этих инструментов не сложно. III.3. Инструменты работы с примечаниями, сносками и гиперссылками Пожалуй, самым нудным и утомительным в вычитке текста является обработка и создание сносок из примечаний. Это – постоянные «прыжки» по тексту – с места текста примечания, вырезая его текст в буфер – на «его» номер в главе, удаление этого номера, вставки сноски, потом вставка из буфера примечания… И так – «до умопомрачения». Набор инструментов для работы со сносками созданы как раз, чтобы облегчить этот процесс в полуавтоматическом режиме. Доступ к ним – либо через меню OooFBTools, либо – через панель инструментов Генерация сносок или гиперссылок (иконки со временем могут измениться): 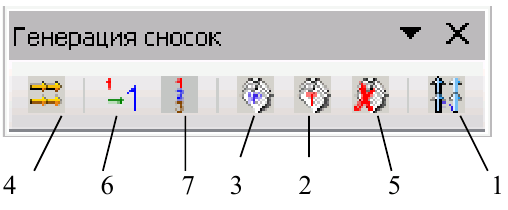 1. Генерация Сносок или Гиперссылок на примечания. 2. Вставка закладки для списка примечаний. 3. Вставка закладки для главы с № примечаний. 4. Преобразование № примечаний в верхнем индексе по шаблону. 5. Удаление всех служебных закладок. 6. Интерактивное преобразование номеров примечаний в верхнем индексе по шаблону 7. Нумерация выделенных абзацев. И инструмент Генерация сносок или гиперссылок и инструмент Преобразование № примечаний в верхнем индексе по шаблону активно используют работу с буфером обмена (Cut, Paste) и реальным положением видимого курсора экрана! Поэтому, пока программа не завершит работу, ничего не делайте ни с мышкой, ни с клавиатурой! Инструмент Преобразование № примечаний в верхнем индексе по шаблону работает и с текстом, и с таблицами, т. е. цифра в верхнем индексе может преобразовываться в шаблонный вид и из ячеек таблиц. Врезки – игнорируются. Инструменты Генерация сносок или гиперссылок и Нумерация выделенных абзацев работают только с текстом документа. Текстовые Врезки – игнорируются, т. к. OOoWrither не позволяет в них вставлять сноски. Таблицы тоже игнорируются (из-за сложности проверки выхода курсора за пределы Таблицы и некорректности получаемого результата). Теперь – подробнее о каждом инструменте. 1. Генерация сносок или гиперссылок Механизм работы Генератора Сносок и Генератора Гиперссылок одинаков. Различие состоит в том, что Генератор сносок перемещает текст примечания в сгенерированную сноску, а Генератор гиперссылок формирует из соответствующего места книги гиперссылку на нужное примечание, ничего не делая с самим текстом примечания. Переключение между ними осуществляется с помощью «залипающих» кнопок. А. Генератор сносок 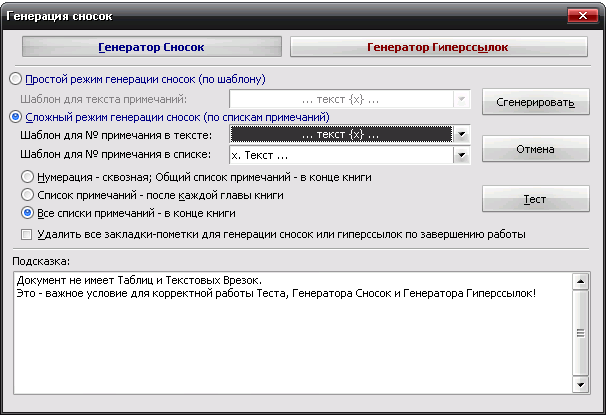 Есть 2 основных режима генерации сносок: Простой и Сложный. 1.1. Простой режим генерация сносок (по шаблону) 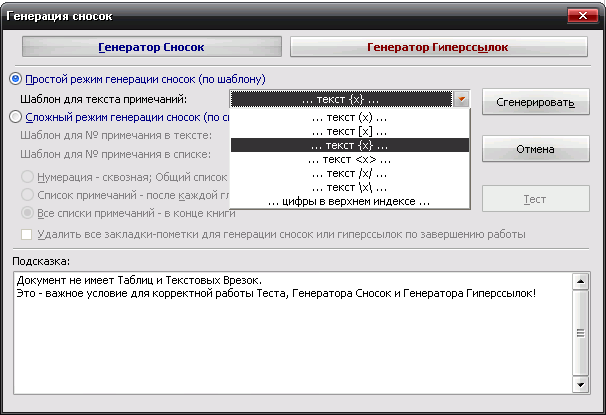 Генерация сносок в этом режиме возможно в выделенных фрагментах текста (их может быть сколько угодно), либо во всем документе. При запуске генерации сносок, если нет ни одного выделения в тексте, появится окно с вопросом, обрабатывать ли весь текст? Если нажать кнопку OK, то будет обработан весь документ. Если – Отмена, то работа остановится, и вы можете выделить нужные области текста. Если выделения есть, то программа ничего не запрашивает, а производит обработку всех этих выделений. В каких случаях используется простой режим генерации сносок? Очень часто источник цитаты или мысли, на которую ссылается автор книги, находится в скобках (круглых, квадратных и т. д.). А это как раз и есть «кандидат» на сноски. Например, есть текст книги (Рыбаков, Язычество древней Руси): К предметам, связанным с бытом волхвов, следует отнести находки неолитических кремневых орудий и стрел. Такая находка была сделана В. А. Городцовым в вятическом кургане у с. Барыбина. Исследователь сопоставил её с обычаем хоронить колдунов с "громовыми стрелами". (Городцов В. А. Археология. Каменный период. М., 1923, с. 77-78.) Обычно под громовыми стрелами подразумевают фульгуриты, но вполне вероятно, что к ним причисляли и изделия каменного века. Подобные находки есть и в других местах. Особый интерес представляет кремневый наконечник копья, найденный в Новгороде в слоях рубежа XIII-XIV вв. Кремень оправлен в серебро с чернью. М. В. Седова определяет дом, в котором найден этот талисман, как дом волхва, так как в его фундаменте зарыты 4 детских черепа. (Седова М. В. Амулет из древнего Новгорода. – Сов. археология, 1957, № 4, рис. 1. с. 166-167.) Наличие православного восьмиконечного креста на серебряной оправе говорит о любопытном синкретизме представлений этого колдуна-знахаря. Запустив диалог Генерации сносок, выбираем «Простой режим генерации сносок (по шаблону)». А в нем – из выпадающего списка – шаблон для текста сносок (в нашем случае – это текст внутри круглых скобках). Нажав кнопку Сгенерировать мы получаем текст, где вместо круглых скобок стоит очередная сноска, а в тексте сноски – текст из круглых скобок:  Этот текст содержит в скобках только ссылки на источники – книги. Но в реальных книгах после OCR встречается ситуация, когда в скобках (или других идентификаторах из шаблона) находятся не только ссылки на авторов книг, но и уточнения, пояснения… Если запустить Простой режим генерации сносок для всего документа, то и эти уточнения и пояснения тоже обработаются, как кандидаты на сноски. А это не то, что мы ожидаем. Для решения этой проблемы есть 2 пути. 1). Круглые скобки вокруг авторов книг заменить на фигурные, или другие идентификаторы из списка шаблона. 2). Выделять только те фрагменты книги, где в скобках находятся действительно кандидаты на сноски, и не выделять те, которые являются уточнениями и т. д., хотя и находятся тоже в таких же скобках. Тогда они и не будут преобразованы в сноски. Вот пример текста (в нем, для иллюстрации, желтым маркером выделены кандидаты на сноски, а оранжевым – уточнения, которые не должны быть обработаны, как сноски):  Значит, нам надо курсором выделить только кандидатов на сноски (на картинке – желтый маркер), используя клавишу Ctrl:  Точность выделения не имеет значения – главное – чтобы наши идентификаторы (в данном случае круглые скобки) попали в это выделение. Теперь, после генерации сносок в Простом режиме генерирования получаем следующее:  Как видим, все получилось, как надо. Использование выделений в тексте довольно удобно, когда не надо обрабатывать весь документ. Идеально было бы, если бы все идентификаторы кандидатов на сноски отличались бы от круглых или квадратных скобок. Тогда можно просто обработать весь документ, не думая о том, чтобы под обработку не попали и уточнения в круглых скобках, или страницы оригинала в квадратных скобках. 1.2. Сложный режим генерация сносок (по спискам примечаний) Сложный режим генерации сносок делится на 3 вида (по виду книг с примечаниями): 1). Нумерация примечаний в Тексте – сквозная; Общий Список примечаний – в конце книги. 2). Список примечаний – после каждой главы книги. 3). Все списки примечаний – в конце книги. 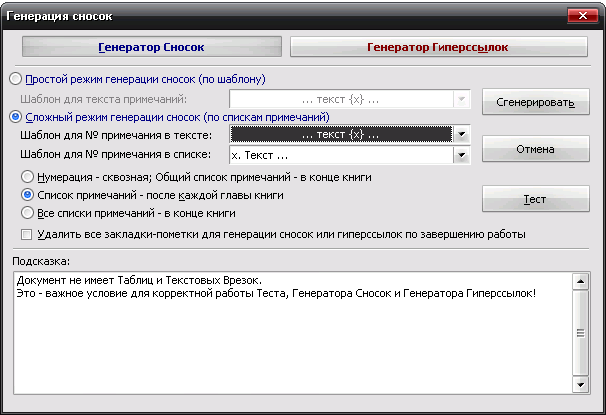 Для каждого из этих вариантов расположения блоков текста примечаний можно выбрать Шаблон для номера примечания в тексте: 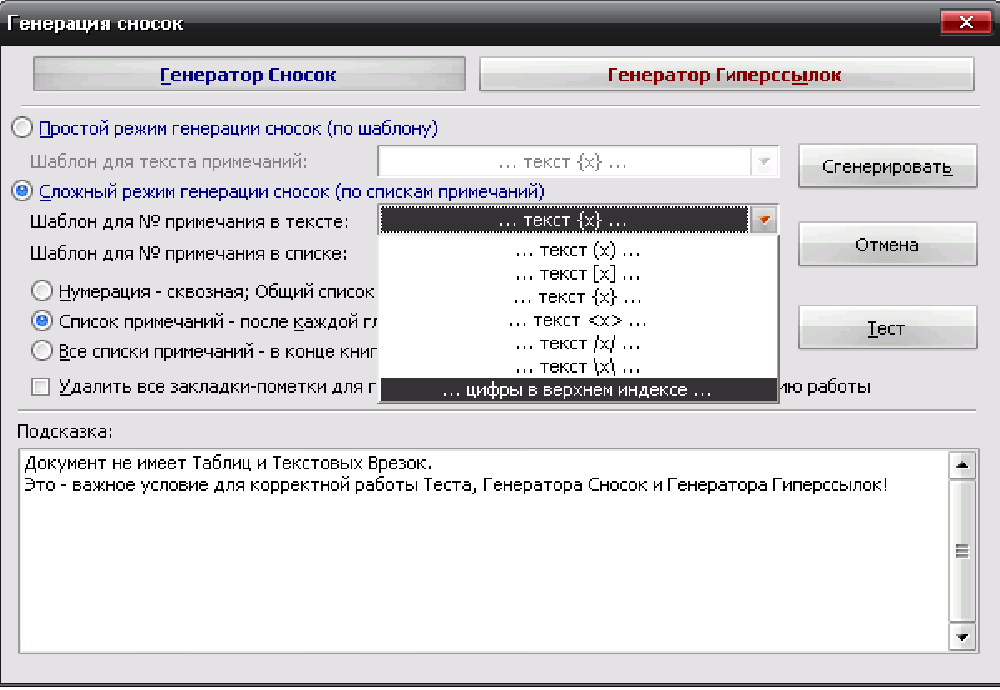 И Шаблон для номера примечания в списке примечаний: 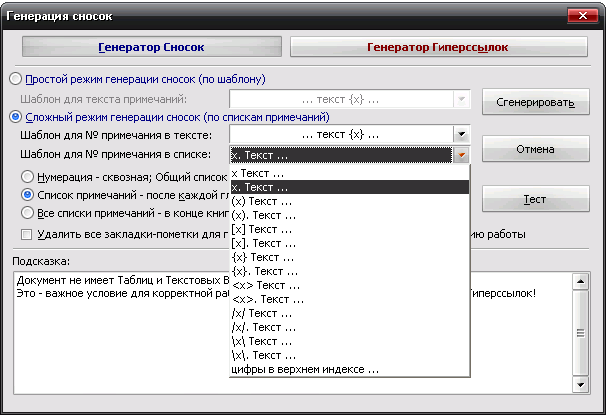 В Сложном режиме генерации сносок обрабатывается весь документ. Обработка выделенных фрагментов текста не предусмотрена, т. к. она избыточна. Нужные зоны поиска задаются закладками (об этих инструментах см. ниже). При генерации сносок ищется соответствие номеров примечаний в главах с номерами этих примечаний в списке примечаний по каждой главе. Если такое соответствие не найдено, то в списке примечаний такое примечание остается, не удаляется. 1.2.0. Очень ВАЖНО: корректность документа для сложной генерации сносок! Корректность работы Генератора сносок и/или Теста в режиме сложной генерации зависит от наличия (вернее – отсутствия) Таблиц и/или Текстовых Врезок в Списках примечаний (эти области документа отмечены закладками _ooo_ocr_tc_foot_note_list_zone_dikbsd_… _ooo_ocr_tc_foot_note_list_zone_dikbsd_1… _ooo_ocr_tc_foot_note_list_zone_dikbsd_N)[1]: 1. OOo Writer не может вставлять Таблицы в сноски. 2. Таблицы и Врезки «путают» Тест и Генератор сносок – результат может быть не верным или вообще – программа «вылетает». Поэтому, если в Документе есть хоть одна Врезка или Таблица, то выдается сообщение- подсказка в текстовом поле формы Генератора сносок, что нужно сделать. Дальнейшая работа – на ваш страх и риск. Лучшее – просмотреть Документ, в частности все Списки примечаний (они помечены закладками _ooo_ocr_tc_foot_note_list_zone_dikbsd_… _ooo_ocr_tc_foot_note_list_zone_dikbsd_1… _ooo_ocr_tc_foot_note_list_zone_dikbsd_N – легко найти в Навигаторе OOo – по F5), и откорректировать Списки. Для этого надо в Списках примечаний текст Врезки вынести из нее в текст Списка примечаний, Врезку удалить. Таблицы можно отскриншотить в виде картинки, саму таблицу удалить, а после генерации сносок вставить эту картинку в нужное место нужной сноски. Пример подсказки, если в Документе нет ни одной Таблицы и/или Текстовой Врезки:  Пример подсказки, если в Документе есть хоть одна Таблица и/или Текстовая Врезка:  В этом случае, при нажатии на кнопку Тест или Сгенерировать, выдается запрос на дальнейшую работу:  Если в Списках примечаний Таблиц и/или Врезок нет, но они есть в других частях Документа (Главы книги и т. д.), то не обращайте внимание на это предупреждение, жмите кнопку OK, и все будет OK:-). Но, если в Списках примечаний есть Таблица и/или Врезка, то все же лучше от них «избавиться», как об этом написано выше, и только потом производить Тест и/или Генерацию сносок! В будущем планируется упростить такую проверку на наличие Таблиц и Врезок, чтобы их наличие проверялось только в Списках примечаний (закладка _ooo_ocr_tc_foot_note_list_zone_dikbsd_), а не во всем документе. Тогда лишние подсказки сообщения не будут выдаваться – будет удобнее. А пока – не получается проверить наличие Таблиц и Врезок именно в самой закладке (они там есть, то объект закладки показывает, что их там нет!:-)). Но это – скорее для программистов. Кстати, если кто подскажет, как в закладке определить наличие Таблицы и Врезки (код) – буду благодарен! 1.2.1. Режим 1: Нумерация примечаний – сквозная; Общий Список примечаний – в конце книги К этому виду книг относятся книги, в которых Номера примечаний находятся либо во всех, либо в некоторых главах, а полный сквозной список примечаний для этих номеров находится в конце книги. Схематично это выглядит так: Полный список примечаний – в конце книги 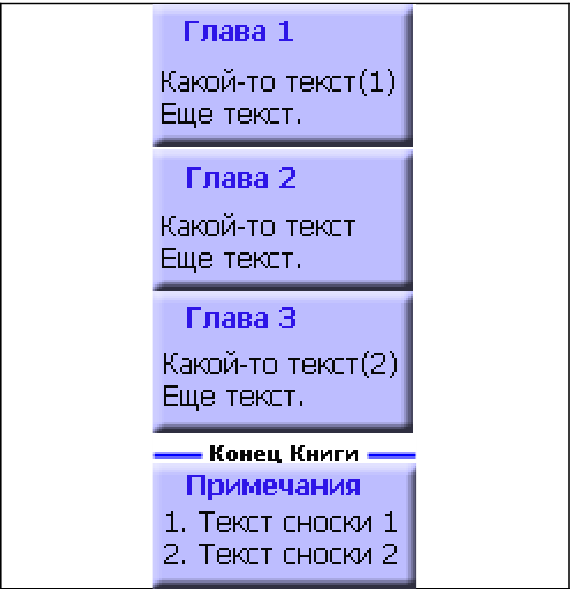 Для того, чтобы генератор сносок «знал», откуда ему брать текст примечаний для каждого номера-ссылки из текста на это примечание, нужно указать список примечаний в конце книги. Сделать это можно, выделив этот список мышкой и поставив на него закладку для списка примечаний (кнопка «Вставка закладки для списка примечаний») – (в таблице ниже этот отрывок текста имеет розовый цвет). Полный список примечаний – в конце книги (с закладкой на Списке примечаний)  Теперь можно запустить генератор. 1.2.2. Режим 2: Список примечаний – после каждой главы книги К этому виду книг относятся книги, в которых Номера примечаний находятся либо во всех, либо в некоторых главах, а список примечаний для этих номеров располагается после той главы, где есть «их» номера примечаний. Схематично это выглядит так:  (1) Расстановка закладок: Инструмент «Вставка закладки для списка примечаний» Для указания программе списков примечаний необходимо соответствующий фрагмент текста выделить мышкой, и нажать на кнопку «Вставка закладки для списка примечаний» (в таблице ниже этот отрывок текста имеет розовый цвет). Этот инструмент интеллектуального типа. Он проверяет, нет ли на этом месте уже такой же закладки. Или, может быть, эта часть текста уже входит в такую же закладку. Или этот выделенный фрагмент текста частично перекрывает уже установленную закладку для списка текста примечаний. В этих случаях выдается соответствующее предупреждение, и закладка не ставится. Это сделано для того, чтобы не было нарушено ВАЖНОЕ соотношение – число глав с номерами примечаний ((1)… (N) и т. д.) не должно отличаться от числа закладок – пометок списков этих примечаний! Если это будет нарушено (часто по невнимательности) – тоже при запуске генерации сносок произойдет следующее: текст примечания главы, например 5, оказался бы применен к главе, например, 3. А это не есть хорошо! Поэтому, следите за вышеназванным соотношением числа глав с № примечаний и числом закладок для их текста! Поставить эту закладку легко. Выделите мышкой фрагмент текста книги, где находится список текста примечаний для конкретной главы. Очень важно, чтобы в эту зону выделения попал ВЕСЬ список, т. е. номер 1-го примечания в этом списке, и последние символы последнего примечания из этого списка. Иначе, то примечание, номер которого лишь частично попал в закладку или вовсе не попал – не будет обработано, а. значит, из него не будет сгенерирована и сноска. (2) Недостающие примечания, ошибки OCR и методы их коррекции Часто приходится вычитывать и конвертировать текст после OCR, который делал кто-то другой. И в этом тексте масса опечаток. То номера сноски в главе нет, то в списке текста сносок имеются не все сноски… Часто бывает и так: есть текст, в некоторых главах есть номера примечаний, а списка текста этих примечаний для этой главы – нет. В идеале – лучше всего найти бумажную книгу и исправить, дополнить текст нужными сносками. Но, если оригинала книги нет, то можно поступить следующим образом. Например, у нас есть такая книг, которая имеет главы с номерами примечаний, а самих примечаний для некоторых глав – нет. Если поставить закладки на имеющиеся списки примечаний и запустить генерацию сносок – то примечания, относящиеся к одной главе, могут быть сгенерированы, как сноски для другой. В таблице дан пример такой книги и метод, как обойти это проблему:  Как видим, в этой книге во 2-й главе есть номера примечаний, а самого списка с текстом этих примечаний в конце главы – нет. Чтобы примечания к главе 3 не сгенерировались, как сноски для 2-й главы, нам надо поставить в конце главы 2 «пустую» закладку для «фиктивного» блока списка текста примечаний. Тогда будет соответствие между главами, содержащими номера примечаний и закладками на списках этих примечаний в конце этих глав. Для добавления «пустой» закладки можно, либо поставить закладку с помощью инструмента «Вставка закладки для списка примечаний» в конец текста главы 2, либо после главы 2 вставить пустой абзац, а на него поставить закладку этим же инструментом. Теперь при генерации сносок каждые примечания будут «приписаны» строго к «своей» главе. Для главы 2 (в нашем случае) вместо номеров примечаний (1) и (2) будут стоять сноски, текст которых будет отсутствовать – «пустые сноски». 1.2.3. Режим 3: Все списки примечаний глав – в конце книги Эта опция выбирается тогда, когда все списки примечаний глав находятся в конце книги. Схематично это выглядит так:  (1) Расстановка закладок: Инструменты «Вставка закладки для списка примечаний» и «Вставка закладки для главы с номером примечания» Работа с закладками в этом режиме Генерации сносок немного отличается от предыдущего. Пометка списков примечаний закладкой с помощью инструмента «Вставка закладки для списка примечаний» ничем не отличается от того, что было написано выше. Отличие состоит только в том, для этого режима генерации сносок требуется использовать еще один инструмент: «Вставка закладки для главы с номером примечания». Для чего нужен этот инструмент? Т. к. в результате ошибок OCR в одной главе, например, 1-й, могут быть номера примечаний с 1 по 10, потом сразу 12 и по 15 (т. е. нет номера 11). А в следующей главе 2 номера примечаний все – с 1-го по 20. Как в этом случае программе «понять», что номера примечаний из 2-й главы: 11, 16-20 не относятся к главе 1? Делать анализ всех списков примечаний для выявления количества номеров примечаний по каждой главе тоже бессмысленно – в главе 1, например 15 примечаний, но из-за ошибок OCR номер 11 примечания отсутствует. А в списке примечаний для этой 1-й главы – всего 3 примечания – 1, 2 и 3-е (тоже из-за ошибок OCR). Как видим, установить соответствие списка примечаний с конкретной главой по числу номеров примечаний невозможно. Поэтому, наиболее лучший способ – это просто «подсказать» программе, где начинается и заканчивается зона поиска номеров примечаний для конкретного списка примечаний. И делается это при помощи инструмента «Вставка закладки для главы с номером примечания». Схематично, документ с 2-мя видами закладок выглядит так: 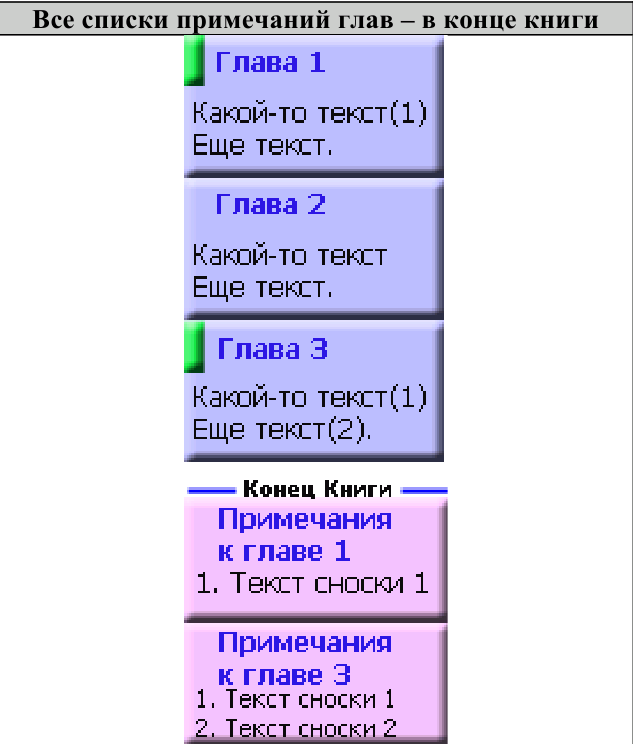 На рисунке зеленым цветом показаны проставленные закладки для главы с номером примечания в начале тех глав, где есть номера примечаний. Эта закладка ставится в самое начало главы (до номера 1-го примечания). (2) В каких случаях ставится Закладка для главы с номером примечания Эта закладка ставится в начало главы только в том случае, если в ней есть номера примечаний, для которых есть список этих примечаний в конце книги. Иными словами, должно быть соблюдено ВАЖНОЕ соотношение – число глав с номерами примечаний, а, значит, и число закладок для этих глав, не должно отличаться от числа закладок – пометок списков этих примечаний! Если это будет нарушено (часто по невнимательности) – то при попытке сгенерировать сноски будет выдано соответствующее предупреждение и программа не запустится. Иначе произошло бы следующее: текст примечаний одной главы оказался бы применен к другой. А это не правильно! Поэтому, следите за вышеназванным соотношением! (3) Примеры неверного проставления закладки для главы с номером примечаний 1). Когда ставят эту закладку в начале главы, где нет ни одного номера примечаний. 2). Когда ставят эту закладку в начале главы, где есть номера примечаний, но нет в конце книги списка примечаний для этой главы (из-за ошибок OCR). 3). Когда ставят эту закладку в начале главы, где нет номера примечаний (из-за ошибок OCR), а в конце книги для нее есть список примечаний. (4) Недостающие примечания, ошибки OCR и методы их коррекции Самый идеальный вариант – это все-таки найти бумажную книгу и восстановить недостающие примечания… Если же это невозможно, то поступить и по-другому. Ниже в таблицах будет схематично показаны некоторые ошибки OCR и пути их коррекции для корректной генерации сносок, когда нет бумажного оригинала книги. 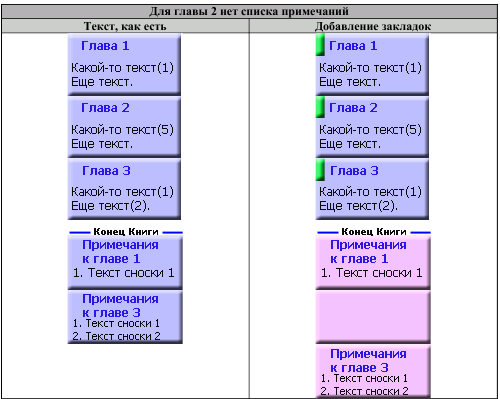 В этом примере в книге всего 3 главы. Во всех главах есть номера примечаний. Но списки примечаний в конце книги есть только для глав 1 и 3. 1). На начало каждой главы, где есть номера примечаний ставим «закладку для главы с номером примечаний» (зеленый цвет на картинке). 2). На списки примечаний ставим «закладку для списков примечаний». 3). Теперь, чтобы при генерации сносок примечания главы 3 не сгенерировались, как сноски главы 2 ставим «пустую» «закладку для списков примечаний» между списком для главы 1 и списком для главы 3 (вставляем пустой абзац, а на него – эту закладку). Теперь – все в порядке.  В этом примере в книге тоже всего 3 главы. Номера примечаний есть только в главах 1 и 3. Списки примечаний в конце книги есть для всех глав. 1). На начало главы, где есть номера примечаний ставим «закладку для главы с номером примечаний» (зеленый цвет на картинке). 2). Ставим «закладку для списков примечаний» только на те списки примечаний, в главах которых есть их номера. Теперь – все в порядке. Конечно, примечания для 2-й главы не будут сгенерированы, как сноски, но это лучше, чем ничего, или. Когда примечания от одной главы сгенерируются, как сноски для другой. Б. Генератор Гиперссылок 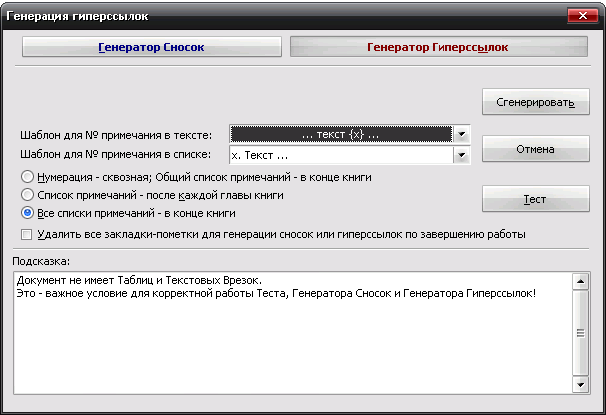 Генератор гиперссылок применяется в том случае, когда по какой-либо причине желательно сделать не сноски из примечаний, а просто переходы из соответствующих абзацев книги на примечания. В этом случае Списки примечаний остаются в тексте, и электронная книга становится максимально похожа на бумажную книгу (кому как нравится). Расстановка закладок и работа режимов генерации – точно такие же, как и для Генератора Сносок в Сложном режиме генерации. Поэтому, не будем повторяться. В. Опция «Удалить все закладки-пометки для генерации сносок или гиперссылок по завершению работы» В диалог Генерации сносок есть опция «Удалить все закладки-пометки для генерации сносок или гиперссылок по завершению работы». Если она включена, то все закладки, поставленные на главы и списки примечаний, автоматически удаляются по окончанию работы. Если эта опция не выключена, то эти закладки остаются. Это удобно, чтобы после генерации сносок посмотреть, а что осталось в списках примечаний (хотя, использовать Тест удобнее)? Для этого с помощью средств OOoWriter (навигатор вызывается по F5) можно переходить от закладки к закладке. Такой «осмотр» полезен: возможно, в главе есть номер необработанного примечаний, только он не соответствует полностью шаблону поиска, и поэтому был проигнорирован. Тогда, после просмотра всех списков примечаний и исправления в заранее сохраненной копии документа всех опечаток, можно снова сгенерировать сноски. Г. Инструмент «Удаление всех служебных закладок» Этот инструмент просто удаляет из документа все оставшиеся, если они есть, закладки- пометки, нужные для генерации сносок. Зачем в обработанном документе уже ненужные закладки? Тем более, что при экспорте в fb2-формат закладки рассматриваются, как id для тэга ‹p› для ссылки-перехода на этот абзац. А это будет явная «пустышка», т. к. на этот абзац перехода не будет (после генерации сносок все уже «ненужные» остатки списков примечаний нужно удалить)… Д. Важные замечания Генераторы сносок и гиперссылок игнорируют Таблицы и Текстовые Врезки. Часто после OCR из-за неправильного экспорта распознанного текста, часть этого текста может оказаться во Врезке. И, если в ней есть номера ссылок на примечания, то этот текст просто необходимо перенести из Врезки в основной текст книги, а саму Врезку – удалить. Тогда и эти номера примечаний будут обработаны генератором. В реальных книгах не так часто встречаются номера примечаний в Таблицах. Если же это есть, то их можно будет после генерации обработать вручную. Е. Тесты к Генераторам сносок и гиперссылок На диалоге Генератора Сносок есть кнопка Тест. Она активна только для сложной генерации сносок. В зависимости от режима генерации выполняются разные тесты. Для чего это нужно? Очень часто книга вычитывается и делается после OCR, когда в тексте может быть масса ошибок, которые могут распространяться и на номера примечаний. Сгенерировав сноски в такой книге можно заметить, что не все примечания обработаны, чего-то не хватает, а какие-то сноски содержат «чужой текст». Чтобы быть уверенным, что сноски или гиперссылки сгенерируются корректно, сначала нужно выполнить тест, немного подождать, потом проанализировать результат (он будет автоматически показан в браузере, стоящем по-умолчанию в системе) в виде html-файла. 1. Примеры ошибок OCR и «ложного срабатывания» генераторов Рассмотренные ниже примеры – результат анализа работы Теста. Запустите Тест, просмотрите результат – повторяющиеся номера, отсутствующие номер и т. д. По этим данным можно многое понять об ошибках в тексте и найти нужные номера примечаний в книге – они в тесте показаны в виде списка. «Ложное» срабатывание генератора – это его абсолютно верная реакция на ошибки или некорректности в тексте книги. (1) Отсутствующие номера примечаний и опечатки Например, для обозначения номеров примечаний в Тексте используются круглые скобки и цифры, а в списке – в начале каждого абзаца номер с точкой после него (самый распространенный вариант книг):  В 1-й колонке – пример корректного текста книги. Есть четкое соответствие между номерами примечаний в Тексте и соответствующими им примечаниями в Списке примечаний (номера выделены синим цветом). Сгенерируется 3 сноски или гиперссылки. Во 2-й колонке таблицы – ситуация, когда в Тексте книги либо нет номера примечания, либо рядом с цифрой – «посторонний» символ, либо закрывающая скобка «распозналась» не как круглая, а как фигурная (эти «дефекты» показаны красным цветом). А генератор «настроен» именно на круглые скобки и цифры внутри них. В этом случае сгенерируется только 1-я сноска (гиперссылка). Все остальное останется нетронутым. В 3-й колонке таблицы – пример плохого экспорта после OCR Списка примечаний – 1-е и 2-е примечания «слиплись» в один абзац, а у 3-го после номера вместо точки стоит запятая. Будет сгенерировано только 1 сноска из 1-го примечания, причем ее текст будет содержать и 1-е примечание, и 2-е, т. к. это один абзац. 3-е же примечание будет вообще не найдено. После исправлений всех этих опечаток все примечания будут корректно сгенерированы в сноски (гиперссылки). (2) Повторяющиеся номера примечаний Часто в текстах можно встретить ситуацию, когда номера примечаний повторяются либо по замыслу автора книги, либо из-за OCR-ошибок, либо гол, весь и другая информация в скобках цифрах воспринимается генератором, как номер сноски. Одинаковые номера-указатели в Тексте – замысел автора книги 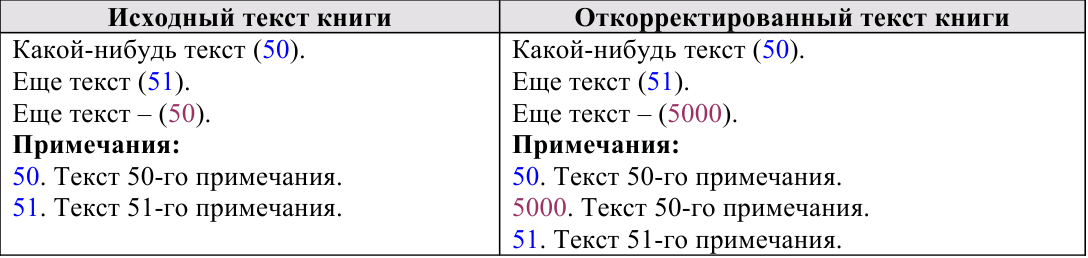 Здесь автор книги дважды ссылается на одно и то же примечание – (50). Это вполне допустимо, но при генерации это 2-е указание на примечание не будет обработано. Чтобы и оно сгенерировалось в сноску, его надо изменить, придав ему заведомо уникальное значение, а в Списке примечаний добавить еще один абзац с текстом от примечаний 50. а номер – изменить на уникальный, как это показано во 2-й колонке таблицы примера. Теперь все будет сгенерировано в сноски корректно. Одинаковые номера-указатели в Тексте – какие-то цифры воспринимаются, как номера примечаний 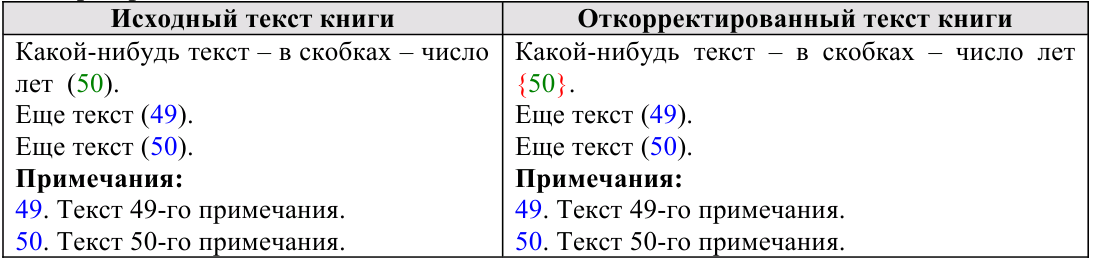 В этом примере рассмотрена ситуация, когда число лет человека, взятое в круглые скобки, воспринимается, как дублирование примечания (50). При генерации сносок именно это число лет (50) будет воспринято, как указатель на примечание из Списка: «50. Текст 2-го примечания». А это – не то, что должно быть. Надо запустить тест, посмотреть, есть ли повторяющиеся номера (будет показан их список, если они есть), и те числа, которые не являются указателями на примечание – как-то выделить особо, чтобы после генерации сносок найти их восстановить их прежний вид. Например, число лет в скобках (50) можно «защитить», изменив круглые скобки на фигурные: {50}. Одинаковые номера-указатели в Тексте – при распознавании (OCR) какой-то номер примечаний распознался неправильно 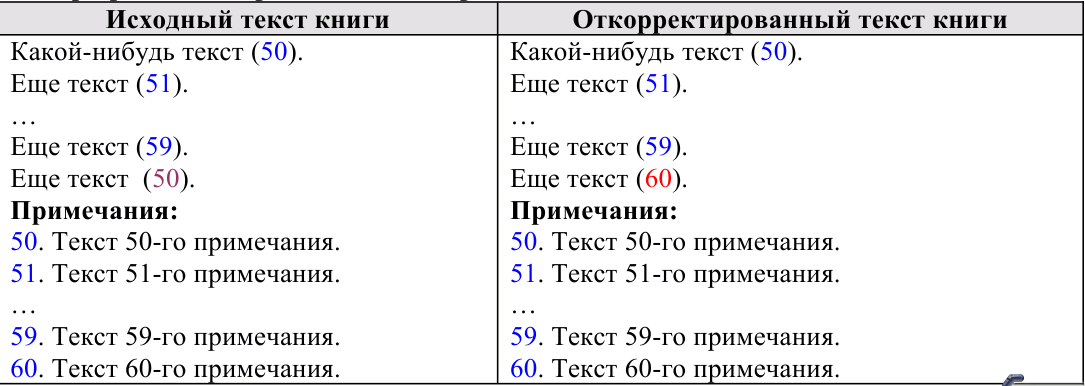 Одинаковые номера-указатели в Списке примечаний – при распознавании (OCR) какой-то номер примечаний распознался неправильно  (3) Несоответствие числа номеров примечаний из Текста числу примечаний в Списке примечаний и наоборот В корректном тексте книги с примечаниями число номеров-ссылок на соответствующие им примечания в Списке примечаний и число примечаний в этом Списке должны совпадать. Иногда Тест может показать, что это не так. Примеры: В Тексте есть отсутствующие номера из Списка примечаний   Тест показал, что номер (58) из Текста отсутствует в Списке примечаний, а номер из Списка примечаний (68) отсутствует в Тексте. В этом примере в Списке примечаний ошибка в номере 68. Вместо этого номера должен стоять номер 58. – это – OCR-ошибка. 2. Книга с номерами примечаний без ошибок В хорошо распознанном тексте должны имеется следующее: 1. Число номеров-ссылок на соответствующие им примечания в Списке примечаний и число примечаний в этом Списке должны совпадать. Если это соотношение не соблюдается – генерация сносок не будет корректной. 2. Все номера примечаний в Тексте должны быть «обрамлены» в одни и те же символы, например круглые скобки. 3. Все примечания из Списка должны идти с начала абзаца и соответствовать шаблону – x. или {x} или (x) или ‹x› и т. д. 4. Число обработанных номеров примечаний должно быть равно числу Уникальных, т. е. не повторяющихся номеров. 5. Должны быть выполнены следующие условия: Число Повторяющихся номеров = 0; Число Отсутствующих номеров = 0; Число Отсутствующих номеров из Текста в Списке примечаний = 0; Число Отсутствующих номеров из Списка примечаний в Тексте = 0 3. Использование данных анализа Теста В генерируемом отчете Теста для каждого из Режимов содержится масса таблиц, помогающих понять – что в книге не в порядке с примечаниями (если таковое есть). Анализ делается в Зонах поиска, помеченной 2-мя закладками – Глава Книги и Список «ее» примечаний. По каждой такой Зоне выдается своя информация нескольким критериям: Сколько обработано номеров примечаний, сколько есть неповторяющихся номеров, сколько повторяющихся, сколько отсутствующих, и в Главе, и в Списке «ее» примечаний. А также – сколько и какие номера из Главы отсутствуют в Списке примечаний и наоборот. По всем эти данным выдаются таблицы с соответствующими номерами. В конце отчета – важные таблицы – какие Зоны (Главы и «их» Списки примечаний) не требуют корректуры (с ними все в порядке), а какие – требуют исправления ошибок для успешной генерации сносок. В этих таблицах отображаются названия закладок, по которым с помощью Навигатора в OpenOffice.org (вызывается по F5) можно легко перейти в нужное место и исправить ошибки в нумерации примечаний и т. д. Пользуйтесь этой информацией!!! 4. Важное замечание о Тесте Часто пользователь может по невнимательности ошибочно выбрать не тот режим сложной генерации сносок (гиперссылок), сделать Тест, а потом удивляться, почему тест выдал «странные» данные – то нет вообще ни одного номера примечаний (а в Документе они есть), то число уникальных (неповторяющихся) номеров примечаний в Главе или Списке примечаний вообще нет! И т. д. Чтобы этого не было четко следуйте следующему: 1. Если Книга у вас имеет вид: Примечания есть в каждой главе, а Списки примечаний – в конце книги, то в форме Генератора сносок выберите именно этот режим, а не Список примечаний – после каждой главы! Т. е. не ошибитесь с выбором режима генерации сносок (гиперссылок)! 2. Если в Главах Книги номера примечаний отмечены у вас фигурными скобками, например, {1}… {51}, номера примечаний в Списке примечаний – цифрой в круглых скобках без точки после закрывающей скобки, например: (1) Текст примечаний, то в форме диалога в шаблонах нужно выбрать именно такой шаблон! Не перепутайте! Иначе и Тест, и результат генерации сносок (гиперссылок) вас «приятно разочарует»;-). Будьте внимательны! 2. Преобразование номеров примечаний в верхнем индексе по шаблону  Инструмент «запоминает» свое положение на экране и последний выбранный шаблон из списка. Инструмент желательно использовать только для тех книг, где цифрами в верхнем индексе обозначаются только номера примечаний! Иначе, степени в ряде книг: научных и математических книгах, номера стихов в Библии и Коране преобразуются по шаблону, что будет явной ошибкой! Для этих книг лучше использовать Инструмент Интерактивного преобразования номеров примечаний в верхнем индексе по шаблону, который позволяет найти такие цифры, просмотреть найденное и дает возможность вам самим принять решение – номер ли это примечания или нет. Для чего нужен этот инструмент? Очень часто встречаются книги, сохраненные после OCR в формат, поддерживающий верхний индекс текста (rtf, doc…). В таких книгах номера примечаний часто представлены цифрами в верхнем индексе. Инструмент «не понимает», где – номер примечания, а где – степень числа или переменной из формулы. Поэтому применять его нужно осторожно. Или – запомнить, где в тексте встречаются формулы, а потом их исправить. Алгоритм этого инструмента представляет собой анализатор всего документа по абзацам. Поэтому он не предусматривает (пока) поиск в выделенных зонах текста. Лучше всего выбрать шаблон для преобразования номеров примечаний в верхнем индексе, отличный от круглых (x) или квадратных [x] скобок, т. к. в тексте могут встречаться пояснения в виде цифр в этих скобках, и при генерации сносок они могут преобразоваться по шаблону! Лучше избрать шаблон в виде фигурных скобок {x}:  Работа инструмента проста. Просто нажмите кнопку Преобразовать. После работы он выдаст сообщение о числе преобразованных номеров примечаний. P.S. Начиная с OOoFBTools-1.17 этот инструмент Автоматического преобразования становится избыточным, т. к. Генератор Сносок и Гиперссылок «научился» работать и с номерами примечаний в верхнем индексе. Этот же инструмент Преобразования № примечаний в верхнем индексе по шаблону может пригодиться в следующих случаях: 1. Когда вы хотите Генерировать не сноски, а гиперссылки, а эти гиперссылки в виде цифр в верхнем индексе выглядят не очень эстетично, на ваш взгляд. 2. Когда вы не хотите генерировать ни сноски, ни гиперссылки, а просто хотите преобразовать номера примечаний в верхнем индексе к более удобному для вас виду. 3. и т. д. 3. Интерактивное преобразование номеров примечаний в верхнем индексе по шаблону  Этот инструмент полезен в тех случаях, где нельзя использовать инструмент автоматического преобразования номеров примечаний в верхнем индексе (см. выше) – в документе есть математические формулы со степенями (цифры в верхнем индексе) и т. д. Автоматическое преобразование нельзя использовать в таких книгах, как Библия, Коран, математические книги и т. д., в которых цифры в верхнем индексе обозначают номера стихов (Библия, Коран…) или степень числа в формулах. При использовании автоматического преобразования все эти цифры тоже будут преобразованы по шаблону (например, {1}), а это – неверно. Поэтому для таких книг и разработан инструмент интерактивного преобразования номеров примечаний для дальнейшей автоматической генерации сносок в книге (см. соответствующий инструмент выше). Лучше всего выбрать шаблон для преобразования номеров примечаний в верхнем индексе, отличный от круглых (x) или квадратных [x] скобок, т. к. в тексте могут встречаться пояснения в виде цифр в этих скобках, и при генерации сносок они могут преобразоваться по шаблону! Лучше избрать шаблон в виде фигурных скобок {x}: Как он работает? Поиск осуществляется от местоположения видимого курсора, и движется «по кругу». Нажатие кнопки «Найти» выделяет найденные цифры в верхнем индексе. Если эти цифры действительно имеют отношения к номерам примечаний, то для их преобразования есть два выпадающих списка шаблонов и две соответствующие этим спискам кнопки преобразования. Если включена опция «Искать далее после обработки найденного», то после нажатия одной из кнопок преобразования найденное будет преобразовано по шаблону и будет автоматически найдены другие цифры в верхнем индексе. После OCR цифрами в верхнем индексе в книге могут обозначаться не только номера примечаний, но и номера сносок в списках текста сносок. Например:  Здесь – и номера примечаний в тексте (сноски), и номера примечаний в списке примечаний – в верхнем индексе. Инструмент найдет все такие номера. И, для каждого из этих 2-х видов цифр в верхнем индексе предусмотрен свой шаблон преобразования и соответствующая ему кнопка преобразования. Например, для этого текста на картинке, после ручной обработке с шаблонами, показанными на картинке выше результат будет таким:  Теперь такой текст легко может быть использован для работы автоматического генератора сносок (см. выше). В инструменте предусмотрен выбор поиска либо цифр в верхнем индексе, либо любых символов в верхнем индексе. Последнее часто бывает очень полезно, т. к. после OCR многие цифры примечаний «распознаются, как случайные символы верхнего индекса. Инструмент найдет и их… 4. Нумерация выделенных абзацев  Инструмент написан по следующим причинам: 1. Разработчики OOo Writer очень часто меняют свойства и методы многих объектов и, в частности, нумерованных списков, из-за чего пакет OOoFBTools перестает нормально обрабатывать нумерованные списки. 2. Инструмент автогенерации сносок или гиперссылок не может работать с нумерованными списками. Поэтому, нумерованные списки можно очень просто заменить на абзацы с нумерацией. Данный инструмент позволяет пронумеровывать либо весь документ, либо 1 или несколько выделенных фрагментов текста. Он игнорирует Таблицы, Текстовые Врезки и Сноски (внизу страницы). Можно задать начальный номер для самого первого абзаца. Можно сделать Сквозную нумерацию для нескольких выделенных областей текста, если включить соответствующую опцию. Если обрабатываемый абзац – нумерованный список, то автонумерация отключается. Если же этот абзац – простой абзац, то он пронумеровывается без автонумерации. Т. е. в любом случае для обрабатываемых абзацев автонумерация отключается! Можно задать вид нумерации (полезно для последующей автогенерации сносок или гиперссылок). Скажу от себя – мне этот инструмент экономит массу времени! III.4. Вставка символа маркера () в начало заданных абзацев  Данный инструмент позволяет делать следующее: 1. Вставлять в заданные абзацы текста символ маркера . 2. Обрабатывать либо выделенные абзацы, либо весь документ. 3. Обрабатывать либо только маркированные абзацы, либо любые не маркированные абзацы, либо – и те и другие. Когда инструмент находит маркированный абзац, он удаляет из него маркер и его признак. Очень часто после OCR, некоторые виды маркеров в тексте экспортируются в fb2-файл не корректно, что проявляется их «кривым» отображением в читалках. Данный инструмент решает эту проблему. Экспорт теста с маркерами требует кодировки UTF-8, что влечет за собой увеличение размера результирующего fb2-файла. Используя данный инструмент можно заменить все маркеры на символ маркера, что позволит делать экспорт текста в кодировке Windows-1251 для уменьшения размера fb2-файла. Конечно, при условии, что в тексте отсутствуют Юникодные символы. III.5. Замена простых пробелов на неразрывные Инструмент вызывается либо из меню OOoFBTools. Либо на нажатию кнопки на панели инструментов. Такая замена пробелов полезна, когда в документе простыми пробелами заданы структуры текста. В fb2-файле простые пробелы после конвертации сохраняются, но читалки и fb2-редакторы "воспринимают" множественные простые пробелы, как один. Тем самым структура текста нарушается. Данный инструмент просто заменяет все простые пробелы на неразрывные (сохраняя их число) либо в выделенных фрагментах текста, либо во всем документе. Не рекомендуется производить замену во всем документе: 1. Замена происходит медленно – посимвольно. Этот алгоритм вполне достаточен для обработки небольших фрагментов текста. Поэтому для обработки большого объема текста потребуется много времени. 2. Часто множественные пробелы в тексте встречаются из-за неправильного форматирования (обработка текста из Интернета, после OCR и т. д.). Зачастую они не несут никакой смысловой нагрузки. Если же все простые пробелы заменить на неразрывные, то в читалке текст fb2-файла с множественными неразрывными пробелами будет выглядеть некрасиво. Поэтому все множественные простые пробелы лучше заменить на один простой пробел с помощью инструмента Корректор Текста. А потом уже можно задавать нужные вам структуры текста, отбивая уровни пробелами, которые легко и быстро заменяются данным инструментов в выделенном фрагменте текста. Примечания:1 В названия служебных закладок входит Ник автора пакета OooFBTools. Это сделано не из-за тщеславия автора,-) а для того, чтобы максимально исключить вероятность наличия в обрабатываемом документе одноименных закладок. |
|
||
|
Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Другие сайты | Наверх |
||||
|
|
||||