|
||||
|
|
БЕСЕДА ЧЕТВЕРТАЯ ДИФФЕРЕНЦИАЛЬНЫЙ АЛГОРИТМ ЧТЕНИЯ Что значит понять текст? Один из древних китайских авторов Цзи Юнь писал: «…Книги читают для того, чтобы постичь высшие принципы, а высшие принципы постигают, чтобы применить их в жизни. Если же впитывают прочитанное, не вникая в суть, доходят до такой тупости, что причиняют вред другим людям». В одном из преданий, записанных мудрецами Индии, сказано: «Тот, кто усиленно стремится собирать науки и читать книги без размышления о том, что он читает, достоин того, чтобы его постигло то же, что постигло одного человека». Ученые говорят, что он проходил мимо какой-то пещеры и ему попались следы клада. Он начал рыть и напал на большое количество золота и серебра. Он подумал: «Если я возьмусь переносить это богатство, то извлечение его и занятие переноской лишат меня того наслаждения, которое я могу от него получить. Я лучше найму людей, которые перенесут его в мое жилище; сам я буду последним и не оставлю за собой ничего, что занимало мою мысль переносом или какими-нибудь действиями. Таким образом, я получу избавление тела от труда за незначительную плату, которую вручу им». Потом он пришел с носильщиками и стал передавать каждому из них столько, сколько тот мог снести, и говорил ему: — Ступай с этим к моему жилищу. Носильщик, однако, шел к своему собственному дому и обманывал его. Когда же от клада больше ничего не оставалось, он сам пошел к своему жилищу и не увидел там никаких денег, обнаружив, что каждый из носильщиков воспользовался унесенным для самого себя; ему же от этого досталась только забота и утомление, потому что он не подумал о конце своего дела. Подобно этому и тот, кто читает эту книгу, не понимая ее цели, явной и тайной, не воспользуется тем, что ему выпадает на его собственную долю. Приведенное выше высказывание взято из литературного памятника древности «Калила и Димна». Изречения и мудрости, содержащиеся в этой книге, поражают и сегодня глубиной философских обобщений различных направлений деятельности людей и общества. Как и многие другие памятники древности, эта книга отражает эволюционные особенности человеческого мышления, демонстрируя проявление психических закономерностей восприятия внешнего мира, объективно изученных современной наукой. Проблема «понимание — непонимание» является, пожалуй, одной из центральных во многих философских течениях. Естественно, что каждое учение, излагая свои постулаты, стремится сделать их доступными широким читательским массам. Видимо, этим и можно объяснить то большое значение, которое придается в документах древности пониманию текстов. Стремление выделить эту проблему в отдельное направление привело к возникновению нового толкования науки герменевтики. Согласно античным мифам, одним из «прислужников богов» и вестником их воли в отношении людей был легендарный Гермес. От имени этого мифологического «переводчика» и происходит наименование герменевтики как искусства толковать непонятное и даже искаженное, объяснять смысл чужого языка или знака. Вот как определяет современная герменевтика процесс понимания текста. Звуки и буквы, комбинации символов и даже предложения сами по себе несущественны для понимания. С информационной точки зрения они представляют собой лишь сигналы. Мы понимаем не звуки, буквы и символы и Даже не слова и предложения сами по себе, а мысль, которую они выражают, тот смысл, который содержится в словах и предложениях языка. Таким образом, понимание текста связано с раскрытием его смысла или значения. Чтобы раскрыть этот смысл и, следовательно, понять текст, необходимо выполнить определенные действия. Проблема понимания текста достаточно давно и плодотворно исследуется психологами. Что же такое понимание? Психологи называют пониманием установление логической связи между предметами путем использования имеющихся знаний. При чтении несложного текста понимание как бы сливается с восприятием — мы мгновенно вспоминаем полученные ранее знания (осознаем известное значение слов) или отбираем из имеющихся знаний нужные в данный момент и связываем их с новыми впечатлениями. Но очень часто при чтении незнакомого и трудного текста осмысление предмета (применение знаний и установление новых логических связей) представляет собой сложный, развертывающийся во времени процесс. Для осмысления текста в таких случаях необходимо не только быть внимательным при чтении, иметь знания и уметь их применять, но и владеть определенными мыслительными приемами. При необходимости запомнить текст человек вначале старается лучше понять его и применяет для этого различные приемы. Чаще всего читатели используют три основных приема: выделение смысловых опорных пунктов, антиципацию и реципацию. Деление текста на части, их смысловая группировка и приводят к выделению смысловых опорных пунктов, углубляющих понимание и облегчающих последующее запоминание материала. Психологи выяснили, что опорой понимания может быть все, с чем мы связываем то, что запоминается или что само «всплывает» как связанное с ним. Это могут быть какие-то второстепенные слова, дополнительные детали, определения и т. п. Любая ассоциация может быть в этом смысле опорой. Смысловой опорный пункт есть нечто краткое, сжатое, но в то же время служащее основой какого-то более широкого содержания. Понимание сводится к тому, чтобы схватить в тексте основные идеи, значимые слова, короткие фразы, которые предопределяют текст последующих страниц. Свести содержание текста к коротким и существенным логическим формулам, отметить в каждой формуле центральное по смыслу понятие, ассоциировать понятия между собой и образовать таким путем единую логическую цепь идей — вот сущность понимания текста. Прием выделения смысловых опорных пунктов представляет собой как бы процесс фильтрации и сжатия текста без потери основы. С помощью этого приема нами разработан дифференциальный алгоритм чтения, который будет подробно рассмотрен ниже. Другой прием, используемый для дальнейшего осмысления читаемого текста, называется антиципацией или предвосхищением, т. е. смысловой догадкой. Что же такое антиципация? Это психический процесс ориентации на предвидимое будущее. Он основан на знании логики развития события, усвоении результатов анализа признаков, предварительно осуществленного оперативным мышлением. Антиципация обеспечивается так называемой скрытой реакцией ожидания, настраивающей читателя на определенные сенсомоторные действия, когда по тексту для этих реакций, казалось бы, нет достаточных оснований. Как показали исследования, в результате специальной тренировки возможно развить у читателя способность мгновенно предугадывать по неопределенным косвенным смысловым признакам текста «наступающие события». Неопределенный сам по себе сигнал благодаря реакции антиципации превращается в субъективно определенный, значащий признак вполне конкретной ситуации развития сюжета (темы) повествования. Квалифицированный читатель по нескольким начальным буквам угадывает слово, а по нескольким словам — фразу, по нескольким фразам — смысл целого абзаца или даже страницы. Игорь Северянин в стихотворении «Отличной от других» так определил способности своей героини: Ты способна и в сахаре выискать «соль», Явление антиципации возможно только в том случае, когда мышление активно работает в продуктивном режиме. При таком чтении читатель в большей степени опирается на содержание текста в целом, чем на значение отдельных слов. Главное — это осмысление идеи содержания, выявление основного замысла автора текста. Явление антиципации закономерно и в значительной степени объясняется избыточностью текста, составляющей, как мы уже знаем, 75 %. Таким образом, при обучении быстрому чтению способность антиципировать является основным фактором формирования своеобразного чутья к фразовым стереотипам и накопления достаточного словаря текстовых штампов. Выявление фразовых стереотипов — одна из первых предпосылок выработки автоматизма смысловой обработки текста. Третьим приемом, который используют читатели для запоминания текста, является реципация, или мысленный возврат к прочитанному под влиянием новых мыслей, возникших в процессе чтения. Этот прием следует отличать от регрессий, так как мы знаем, что регрессии — механические непроизвольные повторы, которые не способствуют лучшему пониманию. Однако очень часто, прочитав какое-то положение и продолжая чтение, читатель мысленно возвращается к предыдущим высказываниям автора, связывая их с новыми, изучаемыми в данный момент. Такой мысленный возврат способствует более глубокому пониманию изучаемого текста. Существуют специальные тексты, измеряющие способность к антиципации, т. е. к смысловой догадке. Предлагаем вам измерить это качество у себя. Задание. Определение способности к антиципации. (На выполнение этого теста отводится только 2 минуты.) Прочитайте текст, заполняя пропущенные места словами по смыслу. Внимание! Вы включили секундомер. Начали: Над городом низко повисли снеговые ______. Вечером началась ______. Снег повалил большими______. Холодный ветер выл как _______, дикий______. На конце пустынной и глухой______вдруг показалась какая-то девочка. Она медленно и______пробиралась по _______. Она была худа и бедно______. Она продвигалась медленно вперед, валенки хлябали и______ей идти. На ней было плохое______ с узкими рукавами, а на плечах______. Вдруг девочка______и, наклонившись, начала что-то______у себя под ногами. Наконец, она стала на______и своими посиневшими от______ручонками стала ______по сугробу. (Правильное решение теста и оценку результатов см. в приложении 4.) Фильтрующая способность мозга Рассмотренные приемы понимания текста интуитивно использует большинство читателей. Целенаправленное же обучение им значительно повышает продуктивность осмысления различных текстов. При быстром чтении понимание текста носит активный и свернутый характер и использование данных приемов осмысления, безусловно, полезно. Остановимся более подробно на некоторых особенностях процесса понимания. При этом, как и ранее, будем опираться на известные науке закономерности работы мозга. Понимание — один из результатов умственной деятельности. Если человеческое мышление — переработка полученной информации, то понимание определяет полноту и эффективность этой переработки. Мало только увидеть какой-либо предмет. Осмыслить его содержание и осознать назначение — конечная задача человека. Эта особенность работы мозга при чтении известна уже давно. В стихотворении австрийского поэта Р. М. Рильке «Поворот» есть такие строки: … Зренье свой мир сотворило, Заменив слово сердце словом мозг, мы получим модель усвоения информации человеком. В самом деле, мозг человека — хранилище разнообразной информации, накопленной в результате опыта и обучения, которой человек пользуется в течение всей жизни. Каждую секунду он извлекает из этого гигантского хранилища нужные сведения. И при чтении текста человек не только получает новую информацию, но и воспроизводит из глубин памяти уже имеющуюся. В коре головного мозга сливаются как бы два потока информации — внешней и внутренней. Как же происходит их последующая обработка? Мы уже знаем, что в основе работы головного мозга лежит взаимодействие различных структур коры больших полушарий — правого и левого. Мозг фильтрует информацию, сжимает ее, освобождая от излишней. На стадии обработки поступающей информации в человеческом мозге есть специальный функциональный алгоритмический фильтр, который не пропускает для дальнейшей обработки бессмысленные словосочетания. Пока еще никто не измерил эффективности использования этого тонкого механизма в человеческом мышлении. Однако есть основание полагать, что потенциальные возможности такого фильтра большинство людей используют очень слабо. При чтении человек должен мгновенно оценить смысловую сторону сообщения И наметить пути дальнейшей его обработки. Причем характерно, что формальная грамматика текста данного языка не имеет существенного значения для восприятия смысла. Так, если составить бессмысленную фразу, хотя и грамматически правильную, то она не будет обрабатываться. Например: «лиловые идеи яростно спят». И наоборот, словосочетание, даже построенное с нарушением грамматических норм, но легко поддающееся осмыслению, воспринимается и обрабатывается успешно. Например: «Моя твоя не понимай». Это обстоятельство было отмечено и выдающимся советским психологом Л. С. Выготским, который говорил, что необходимо уметь различать законы развития смысловой стороны речи и ее внешнего физического оформления, выражающегося в правилах построения предложений, правилах грамматики и т. п. То, что с точки зрения грамматики языка является ошибкой, может иметь психологическую ценность на уровне мышления. В доказательство этого он приводил строки из стихотворения А. С. Пушкина: Как уст румяных без улыбки, Знаменитое чеховское предложение: «Подъезжая к сией станции… у меня слетела шляпа» — также дает пример такого психологически понятного, но грамматически неправильного предложения. Рассмотренная закономерность работы мозга объясняет и тот факт, что человек в любом, даже, казалось бы, в самом бессмысленном выражении пытается отыскать смысл. Известный советский лингвист академик Л. Щерба провел психологический эксперимент. На одной из лекций по языкознанию он предложил студентам изложить содержание следующей фразы: «Глокая куздра штеко будланула бокра и курдячит бокренка». Несмотря на кажущуюся бессмысленность этого предложения, большинство студентов нашли, что в этой фразе говорится о том, что какое-то существо женского пола «наподдало» другому существу мужского пола и продолжает те же действия по отношению к его детенышу. Мы также повторили этот опыт. В одном из экспериментов предложили испыггуемым следующую фразу: «Швыдкая чурла незденко сигла по донку и одвырла чурта с чурятами». И в этом случае большинство испытуемых правильно осмыслили структуру текста. Значение и смысл Разобранные примеры свидетельствуют о том, что осмысление текста — сложный процесс. Вместе с тем он подчиняется определенным законам, обусловленным феноменальными особенностями работы человеческого мозга. Как же использовать эти законы для нашей задачи: научиться при быстром чтении глубоко и полно понимать текст? Чтобы найти пути решения этой проблемы, необходимо вначале решить вопрос о том, что следует понимать в читаемом тексте. Очевидно, некоторым читателям сам вопрос может показаться бессмысленным: понимать нужно все, что содержится в тексте. И вот здесь нас ожидает интересное открытие: текст весь, целиком читать не надо. Чтобы понять его, достаточно прочесть только некоторую его часть, которую можно условно назвать «золотым ядром» содержания. Это именно те 25 % содержания текста, которые остаются после исключения избыточности. Что же представляет собой «ядро»? Чтобы понять это, рассмотрим основные семантические (смысловые) принципы построения текста. Как установила современная лингвистика, тексты обладают единством внутренней логической организации. Они строятся по единым логическим правилам связности изложения. 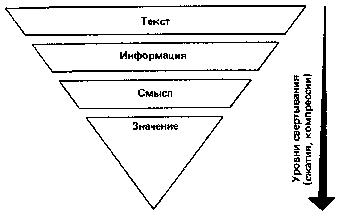 Рис. 11. Уровни сжатия текста Рис. 11. Уровни сжатия текста Кроме того, как мы уже знаем, избыточность текстов доходит до 75 %. Очевидно, «золотое ядро», о котором мы говорим, и несет основную смысловую нагрузку. А если это так, то целевой процесс преобразования текста, т. е. его сжатие, при чтении можно условно считать выделением и формированием этого «ядра». На рис. 11 приведена блок-схема последовательности выполнения этой операции. Текст содержит определенную информацию, которую читатель в нем видит. При описании дальнейших преобразований будем исходить из семантической теории информации, разработанной советским математиком и лингвистом Ю. А. Шрейдером. Согласно этой теории читатель, изучая информацию, сравнивает ее с тем объемом знаний (его еще называют тезаурусом), которым он располагает в данный момент, и дает оценку поступающей информации. Это означает, что если вначале читатель не понял текста, то текст не несет для него никакой информации. Если затем, спустя даже длительное время, получив новые знания, читатель вторично обращается к этому же тексту, то он уже извлекает из него нужную информацию. Что же происходит с ней дальше? В результате изучения текста читатель выделяет смысл, который затем преобразуется в значение. Прежде чем разбирать сущность происходящего далее процесса, необходимо дать объяснение: что же такое смысл и значение? Впервые изучение понятий «смысл» и «значение» предпринял немецкий математик и логик Готлоб Фреге. В 1892 г. вышла его работа «О смысле и значении», которая до настоящего времени не потеряла своей актуальности. Г. Фреге определяет смысл как содержание языкового выражения, т. е. это мысль, содержащаяся в словах. Значением языкового выражения является тот сущностный предмет, который словесно зафиксирован в сознании человека. Например, значением слова Луна по существу является небесное тело или естественный спутник Земли. Согласно концепции Г. Фреге, отношение имени к тому, что оно называет или обозначает, является отношением называния, а вещь, которая называется, является значением этого имени. Всякое имя всегда что-то называет (функция наименования, или номинации), и этим что-то является определенная вещь. Естественно, что могут быть и неназванные вещи. Таким образом, значение — это сущностное свойство имени, которое реализуется путем многообразного называния вещей. Смыслом Г. Фреге называет различие в способе формального обозначения предметов именами. Сочетания слов типа Александр Пушкин, великий русский поэт, поэт, убитый Дантесом различны по смыслу, но одинаковы по значению. В языке вообще и в текстах в частности можно найти разные способы использования имен: педагог — преподаватель; врач — доктор; бегемот — гиппопотам и т. д. Эти примеры сообщают разные сведения об одном и том же. Смысл есть то, что передается и понимается в сообщении как социально значимая информации и что при приеме сообщения должно быть понято однозначно. Два выражения могут иметь одно и то же значение, но разный смысл, если эти выражения различаются по структуре реализации текста. Рассмотрим выражения «5» и «3+2». Смысл в каждом из них различный, а значение — одинаковое. Обратимся вновь к рис. 11. Заключительные этапы преобразования фрагмента текста включают выделение значения из полученного смысла. Означает ли это, что всегда, в любом тексте есть все компоненты этой схемы? Совсем нет. Однако содержание каждого ее элемента идет по убывающей. В самом деле, тексты всегда содержат информацию. Немного можно найти бессмысленных текстов. Но очень многие осмысленные тексты не содержат значения. В литературе по логике обычно приводят пример такого пустого выражения: понятие, выраженное словами король Франции, имеет смысл, но применительно к XX в. значения не имеет. Возможны ли научные тексты подобного содержания? Для ответа достаточно узнать, есть ли значение в цитируемом тексте. Рассмотрим некоторый тотальный и, следовательно, уникальный экземпляр «А». Установление тождества экземпляра с самим собою можно рассматривать как отображение, приводящее образы «А» в соответствии с прообразом «А». Экземпляр «А» по определению может быть сопоставлен только с самим собою. Поэтому отображение является внутренним и, согласно теореме Стилова, может быть представлено в виде суперпозиции топологического и последующего аналитического отображения. Совокупность образов «А» составляет точечную систему, элементы которой являются эквивалентными точками… Как показал анализ, проведенный советским лингвистом И. П. Севбо, формальная связанность и наукообразное звучание не уменьшают пустоты этого текста. Очевидно, теперь мы можем ответить на вопрос о том, что же следует читать в текстах: нужно уметь находить значение. Как же практически научиться выделять значение? Рассмотрим еще одно интересное явление. Как показал Н. И. Жинкин, мозг каждого человека уже обладает этой способностью, так как содержит программу выделения значения в любом читаемом тексте, имеющем смысл. Эксперименты психологов! подтвердили, что при обработке текста человеческий мозг всегда выделяет «ядерное» значение независимо от способа его формального выражения или смысла. Так, в одном из опытов группе испытуемых предлагалось нажимать специальную кнопку каждый раз, как только на экране появлялось слово доктор, и не реагировать на сигнал, если появлялись другие слова, даже сходные по начертанию, например диктор. Большинство испытуемых справились с этим заданием. Затем без предупреждения на экране была показана надпись врач. Практически все нажали кнопку, хотя по начертанию это слово никак не походило на слово доктор. 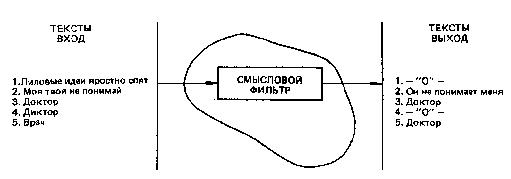 Рис. 12. Фильтрующая способность мозга Рис. 12. Фильтрующая способность мозга Этот пример — доказательство того, что при восприятии текстовой информации мозг реагирует не на языковую структуру слова, а на его содержательную часть. Восприятие мозгом различных словосочетаний показано на рис. 12. Благодаря наличию алгоритмического фильтра мозг не пропускает (выдает на выходе 0) фразу «Лиловые идеи яростно спят». Для фразы «Моя твоя не понимай» формируется соответствующее выражение. И наконец, мозг реагирует одинаково на слова врач и доктор, тогда как для слова «диктор» на выходе также 0. Содержание дифференциального алгоритма чтения При чтении текста мозг формирует «свою трактовку содержания» того, что читается. Происходит перекодирование сообщения на язык собственных мыслей читателя. Мозг выделяет «ядерное», сущностное значение из текста. Однако не всегда эта программа используется эффективно. Вместе с тем только при осмысленном, внимательном чтении текст понимается глубоко и полно. Из этого следует, что при обучении методам быстрого чтения учат произвольно использовать эту принципиально важную программу работы мозга. Как показали эксперименты, знание и умелое применение некоторых упражнений дают возможность извлекать «ядерное» значение в тексте быстро и надежно. Эти упражнения основаны на использовании дифференциального алгоритма чтения. Он показан на рис. 13. Центральное место в этом алгоритме занимает блок, который мы называем доминантой (это слово в переводе с латинского языка означает «господствующий, основной, главный»). Что же такое доминанта применительно к тексту? Ответом на этот вопрос может служить одно восточное предание. Персидский царь, большой любитель книг, имел обыкновение в поездках возить с собой библиотеку, нагруженную на сто верблюдов. Однажды ему показалось это обременительным, и он поручил ста мудрым мужам сделать из этих книг извлечения, которые мог бы поднять один сильный мул. Вскоре, однако, царь приказал мудрецам составить новое извлечение, занимающее одну небольшую книгу, которую всегда можно иметь при себе. Наконец, и это показалось ему неудобным, и тогда снова собрались мудрые мужи. В итоге вместо ста верблюжьих тюков получилось одно остроумное изречение, которое царь стал носить в своем сердце. 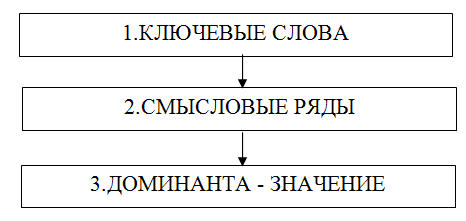 Рис. 13. Три блока дифференциального алгоритма чтения Рис. 13. Три блока дифференциального алгоритма чтения То, что вы прочитаете дальше, не заменяет всех наших бесед, а представляет лишь важнейшую их часть — доминанту: Вы можете повысить скорость чтения в три раза, значительно улучшить качество усвоения прочитанного, развить мышление, внимание, память. Главное, вы научитесь работать так, что каждый раз при чтении текста мозг будет экономно и точно отбирать полезное и нужное из потока воспринимаемой информации. Мы привели здесь пример составления доминанты многих текстов всей нашей книги. Нужно научиться при чтении текста всегда формировать свою доминанту. Как показывают исследования психологов, при чтении текста мозг формирует «свою трактовку содержания» того, что читается. Происходит перекодирование сообщения на язык собственных мыслей читателя. Мозг выделяет «ядерное», сущностное значение из текста. Однако не всегда эта программа используется нами эффективно. Вместе с тем только при осмысленном, внимательном чтении текст понимается глубоко и полно. Следовательно, при обучении методам быстрого чтения нужно научиться использовать эту принципиально важную программу работы мозга. Знание и умелое применение некоторых упражнений дают возможность извлекать «ядерное» значение из текста быстро и надежно. Упражнения основаны на использовании дифференциального алгоритма чтения. Сделаем наше первое «открытие»: что это такое? Открытие, обсуждаемое здесь, состоит в том, что, оказывается, хорошие читатели читают ради понимания смысла, охватывают с одного взгляда много слов сразу, в то время как плохие читатели читают маленькими кусками, охватывая всего одно, два или три слова за одну остановку (фиксацию) глаз. До тех пор, пока кто-то читает вот этим последним дробным способом, он не преуспеет в увеличении скорости чтения; более «длинные», чем, скажем, в одно предложение, мысли оказываются рассеченными на большое количество маленьких кусков, что затрудняет формирование единого, точного понимания смысла фрагмента текста. Как мы уже знаем, интегральный алгоритм чтения облегчает поиск нужной информации в тексте в целом. Для каждого отдельного предложения и абзаца подобную программу, конечно, составить нельзя. Однако для активизации чтения нужно заранее знать, что прежде всего следует отыскивать в каждом смысловом отрезке текста. Для этого и разработан дифференциальный алгоритм чтения. С его помощью можно разбивать каждый формально самостоятельный фрагмент текста на логические отдельные элементы (потому алгоритм и назван дифференциальным). Под отдельным логическим отрезком текста в данном случае мы понимаем каждый смысловой его абзац. Следует помнить, что печатный и смысловой абзацы могут не совпадать. Для облегчения последующей работы рассмотрим каждый из блоков алгоритма отдельно (см. рис. 13). Ключевые слова несут основную смысловую нагрузку. Они обозначают признак предмета, состояние или действие. К ключевым словам не относятся предлоги, союзы, междометия. Очень редко выступают в этой роли и местоимения, которые лишь замещают уже употребляемое ранее в тексте предметное (ключевое) слово. Очень часто смысловой абзац текста в целом является вспомогательным и вообще не содержит ключевых слов. Смысловые ряды. Это пары слов, они состоят из комбинаций ключевых слов и некоторых определяющих и дополняющих их вспомогательных слов, которые помогают в сжатом виде понять истинное содержание абзаца. Именно смысловые ряды являются основой «золотого ядра» содержания текста. Таким образом, при чтении любого текста сознание соединяет ключевые слова в лаконичные, свернутые выражения смысловых рядов, несущие основной замысел автора. Текст как бы мгновенно сжимается, мысленно конспектируется. В нем остаются только зерна мысли, «золотое ядро» на уровне непрерывных цепочек пар слов. Но это только промежуточный этап. Ключевые слова и смысловые ряды выявляются в самом тексте, который пока претерпевает как бы количественные преобразования — сжимается, прессуется. Однако, кроме количественного анализа, сообщение всегда подвергается и качественному преобразованию. Эта интеллектуальная операция соответствует третьему блоку алгоритма — выявлению доминанты. Замечено, что содержание прочитанного при пересказе люди почти никогда не излагают слово в слово. Мозг перекодирует воспринятое сообщение в соответствии с собственным опытом, собственной программой. Такое перекодирование происходит уже в самом процессе чтения. Этим как раз и отличается активное, осмысленное восприятие текста от механической зубрежки. На основе смысловых рядов мозг как бы формулирует сообщение самому себе, придавая ему собственную, наиболее удобную и понятную форму. Таким образом, третий блок алгоритма отражает заключительный процесс перекодирования — выявление ядерного значения содержания текста. Решить эту задачу — значит сформулировать и усвоить действительное значение того, что хотел сказать автор в конкретном отрывке. Выявление истинного значения (доминанты), таким образом, и является основной задачей чтения. Что же такое доминанта? Доминанта — главная смысловая часть текста. Она выражается своими словами, на языке собственных мыслей, является результатом переработки текста, его осмысления в соответствии с индивидуальными особенностями читателя, выявления основного замысла автора. Таким образом, в тексте встречаются слова, которые как бы «подталкивают» вас читать дальше, дальше, предупреждают, что изменений смысла не предвидится. Бывают другие слова, которые «предупреждают» об изменении, «повороте» смысла, «говорят» вам, чтобы вы замедлили скорость чтения, что впереди «крутой поворот». Очень важно знать, как пользоваться такими словами-сигналами. Блоки алгоритма составляют основу логико-семантического анализа текста, который наш мозг выполняет в процессе чтения в значительной степени подсознательно. Есть основания полагать, что эффективность такого анализа у большинства читателей не всегда высока. В самом деле, знание определенной программы еще не означает умение ею пользоваться. Умение пользоваться определенной программой еще не означает возможность ее применения на уровне автоматизированного, неосознаваемого действия-навыка. Задача заключается в том, чтобы образовать именно навык, т. е. доведенное до автоматизма умение грамотно и глубоко анализировать текст в режиме быстрого чтения. Поэтапное формирование навыка и предполагает детальный разбор каждого уровня мыслительных операций при чтении текста с целью выявления его основного смыслового значения — доминанты. Эту задачу и решает дифференциальный алгоритм чтения. Он предлагает в процессе чтения в соответствии с блоками алгоритма производить логико-семантический анализ текста: вначале выделить ключевые слова, затем построить смысловые ряды и, наконец, выделив цепь значений, сформировать доминанту. Цель такого упражнения — показать мозгу, как правильно надо понимать текст. Именно так, и только так можно увидеть главное, действительно важное, проникнуть в суть вещей, явлений, излагаемых автором. Многократное повторение упражнения формирует новый способ кодирования, обеспечивающий затем высококачественное понимание текста в режиме быстрого чтения. Теперь потренируемся: проведем медленное чтение текста, размечая его в соответствии с блоками дифференциального алгоритма чтения. Посмотрим на примере, как используется дифференциальный алгоритм. Наш век не без основания называют веком статистики. Статистика — слово многозначное. Это и набор цифр, полученных определенным образом и характеризующих некоторые явления, и специальная социально-экономическая наука, и научный метод широко применяемый как в общественных, так и в естественных науках. В журналистской работе ко многим темам без статистики совершенно невозможно подойти. В частности, все, относящееся к вопросам народонаселения, прямо-таки основано на статистике. Относительная редкость статей на демографические темы (при громадном интересе к ним и читателей, и общественной важности этих тем) в немалой мере объясняется статистической малограмотностью многих журналистов. Очень часто смысл цифр читателям непонятен. Один пример. Кто не слышал и неупотреблял слов «средняя продолжительность жизни»? Для подавляющего большинства значение их таково: это средний возраст смерти в данное время. Однако истинный смысл их совсем иной: это средняя продолжительность жизни тех, кто родился в данном году, при условии, что на всем протяжении жизни данного поколения возрастные коэффициенты смертности будут такими же, как и в год рождения. Таким образом, эти величина расчетная и условная.. В этом отрывке подчеркнуты ключевые слова. Порядок обработки абзацев этого текста по алгоритму показан в табл. 4. 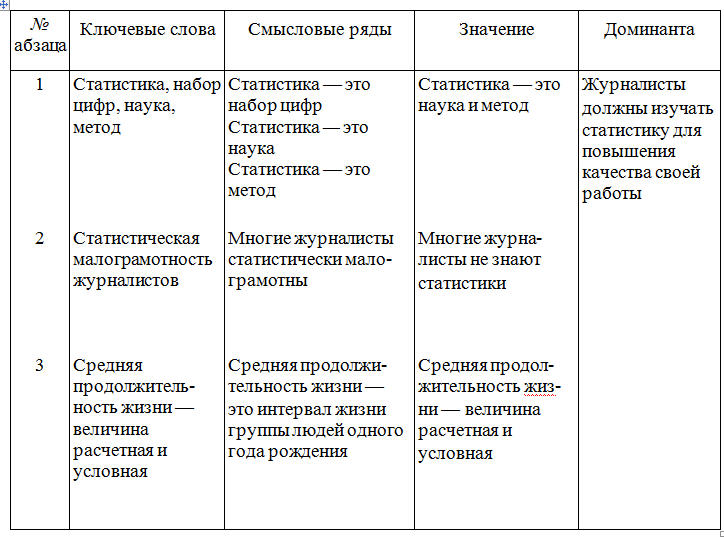 Таблица 4. Разметка текста по блокам дифференциального алгоритма чтения Таблица 4. Разметка текста по блокам дифференциального алгоритма чтения Нужно иметь в виду, что, выполняя упражнения в соответствии с блоками дифференциального алгоритма, мы тренируем мыслительные процессы как бы расчлененно — замедленно и по частям. При чтении они, разумеется, протекают иначе — быстро, одновременно и в значительной мере подсознательно. Но чтобы навык такого чтения стал автоматизированным и мгновенным, тренировать его нужно дифференцированно. Размечая текст по блокам алгоритма, мы с карандашом в руках прочитываем его три раза. При первом чтении подчеркиваем только ключевые слова. Как видно из приведенного выше примера, не все слова текста являются ключевыми, а только те из них, которые будут использованы для последующих построений. Второе чтение используем для построения смысловых рядов: удобно записывать их на отдельном листочке. И наконец, читая текст, а точнее, смысловые ряды, в третий раз формируем значения, из которых складывается затем доминанта. Здесь любопытно провести некоторую аналогию с рекомендациями, которые давали просветители прошлого века для чтения. Так, русский поэт XVIII в. Я. Княжнин советовал: «Читается трояким образом: первое — читать и не понимать; второе — читать и понимать; третье — читать и понимать даже то, что не написано». Формируя доминанту, мы как раз и решаем задачу поиска именно того, что, как говорят, содержится между строк. Иногда говорят: «приценись», прежде чем читать все подряд. Да, именно так, ведь вы присматриваетесь, прицениваетесь, прежде чем купить что-то. Другими словами, предварительно знакомитесь, составляете себе предварительное представление. Тот же самый прием вы применяете к статье или книге, когда ее «покупаете», т. е. собираетесь прочитать. Выполняя упражнения, рекомендуемые ниже, вы убедитесь также, что избыточность текста — вполне реальное, осязаемое явление. Действительно, из всего многообразия слов текста после его графической произвольной разметки в соответствии с алгоритмом остается очень небольшая часть — «сухой остаток», который и составляет основное смысловое содержание. 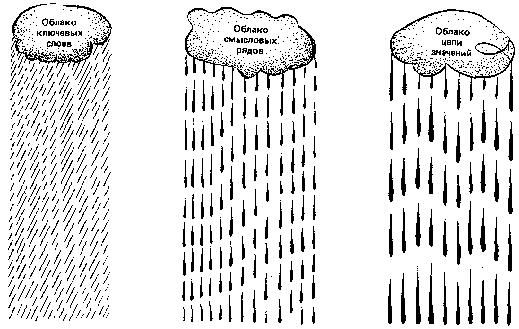 Рис. 14. Пример зрительного дифференциального алгоритма чтения в виде системы облаков Рис. 14. Пример зрительного дифференциального алгоритма чтения в виде системы облаков 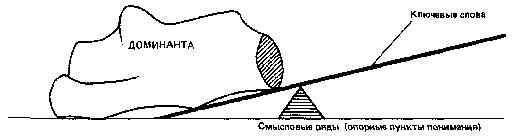 Рис. 15 Зрительный образ дифференциального алгоритма чтения Рис. 15 Зрительный образ дифференциального алгоритма чтения Будучи осмыслен читателем, этот «остаток» преобразуется и принимает вид лаконичного выражения — доминанты. При разработке дифференциального алгоритма мы не предполагали, что может быть дано его зрительное описание. Однако слушатели курсов предложили оригинальное решение зрительного образа алгоритма, что, несомненно, способствует лучшему его пониманию и облегчает его практическое освоение. На рис. 14 алгоритм показан в виде системы облаков. Первые облачка — ключевые слова — разряжаются мелким дождем. Затем они сливаются и образуют облака смысловых рядов, что выражено в крупных каплях, и, наконец, третий образ — туча, которая вмещает в себя все предыдущие облака. Туча значения проливается еще более крупными каплями, а возможно, и градом. Концентрируется смысловая энергия — доминанта текста. На рис. 15 показан еще одни пример зрительного представления алгоритма, который не требует пояснения. Мы рекомендуем вам придумать и изготовить подобные рисунки самостоятельно. Настоящее овладение дифференциальным алгоритмом наступает тогда, когда процесс автоматизирован, т. е. действие не осознается, осмысление текста происходит как бы само собой. Вот впечатление одного из слушателей курсов быстрого чтения: «Слова бегут, словно титры в кино, и понять суть удается иногда как-то вдруг, зацепившись за какое-то ключевое слово. Потом еще такое же слово, и наконец чувствую, что понимаю главное, и значит, многие пустые слова, которые вижу, можно без потерь пропустить… Когда текст бывает очень интересным, чувствую, что отключаюсь от внешнего мира и тут поразительно быстро читаю, все понимаю, запоминаю, и все это сопровождается яркими зрительными образами, картинами. Сущность содержания текста, его смысл и значение выступают тогда ярко и выпукло. Как бы говоришь себе: вот в чем тут дело, это главное, ради чего читал, трудился, тратил время». Дифференциальный алгоритм чтения, определяющий процессы понимания текста, является важнейшим среди приемов техники быстрого чтения. Понять текст — значит не только усвоить его содержание, но и запомнить его. В начале беседы, как вы помните, мы приводили притчу из памятника древности «Калила и Димна». Рассказ о важности понимания текста мы заканчиваем его продолжением, где еще раз с других позиций обсуждается важность этой проблемы: «…Надлежит и читателю этой книги внимательно устремлять взор в нее, чтобы не оказаться подобным одному рыбаку, который был у какого-то залива. Однажды он находился в воде за ловлей, как вдруг заметил раковину и вообразил, что это нечто. Он кинул сеть, которая захватила рыбу, бывшую недалеко, выпустил ее и сам бросился в воду, чтобы достать раковину. Когда же он ее вытащил, то увидел, что была пустой, а не такой, как он думал. И он раскаялся тогда, что оставил находившееся в руках, и горевал о том, чего лишился. На другой день он отошел от этого места и забросил сеть, он поймал маленькую рыбу и старался ее захватить. Опять он увидел дорогую раковину, но даже не повернулся к ней, плохо о ней подумал и оставил ее. По этому месту проходил другой рыбак, нашел ее и взял. Он обнаружил в ней жемчужину, которая стоила больших денег. Первый очень огорчился и до крайности раскаялся в том, что оставил такую ценную раковину. Таковы глупцы, которые пренебрегают размышлением… не останавливаясь над тайнами ее смысла и хватаясь за внешность вместо содержания». Тренировочный комплекс этой беседы включает три упражнения: первое развивает зрительный образ алгоритма, второе — смысловую догадку, явление, которое мы уже обсуждали ранее и получившее название антиципации (предвосхищения), третье предполагает медленное чтение с одновременной графической разметкой текста в соответствии с блоками дифференциального алгоритма чтения. Упражнение 4.1. Зрительный образ дифференциального алгоритма чтения Изготовить рисунок алгоритма по образцам рис. 14 и 15 в двух экземплярах. Один из них укрепить на экране мысленного взора, другой постоянно носить с собой или укрепить перед рабочим столом. Осознать смысл и содержание каждого блока алгоритма. Хорошо представлять себе, что такое ключевое слово, смысловой ряд, доминанта. Упражнение 4.2. Развитие смысловой догадки (антиципации) 1. В статье объемом не более 6 тыс. знаков зачернить слова в начале и в конце каждого предложения. Затем прочитать статью, пытаясь вставить пропущенные слова по смыслу. Упражнение выполняют двое учащихся, причем каждый читает текст, подготовленный другим. 2. Читать страницу книги, закрыв последние пять букв всех строчек текста листом бумаги или линейкой. Затем закрыть начальные пять букв всех строчек и, наконец, первые и последние пять букв строчек текста, стараясь угадать закрытые части по смыслу. Упражнение 4.3. Дифференциальный алгоритм чтения 1. В тексте объемом не более 6 тыс. знаков сделать графическую разметку каждого абзаца в соответствии с алгоритмом. Затем прочитать размеченный текст. При чтении обращать внимание только на ключевые слова. 2. Выполнить разметку еще одного текста и затем прочитать его, стараясь выделить и записать только доминанту. 3. Прочитать контрольный текст № 4. Старайтесь читать этот текст как можно быстрее, без регрессий, находя в тексте ответы на вопросы, поставленные в блоках интегрального алгоритма чтения. Не забудьте отметить время, которое вы затратили на чтение текста, и определить свой коэффициент понимания, ответить на вопросы, указанные в приложении № 5. Особое внимание обратите на формирование доминанты. Подсчитайте скорость чтения по известной вам формуле и запишите ее в своем плане и на графике. Контрольный текст № 4 Объем 4500 знаков СЛОВО — СТУПЕНЬКА К МЫСЛИПонятия собаки и лопаты закреплены в определенных словах — «собака», «лопата». Но совершенно не обязательно и было бы очень серьезной ошибкой отождествлять (как это иногда делается) понятие и значение слова. Во-первых, понятие может быть выражено не только отдельным словом («собака») или словосочетанием («железная дорога»), а, например, предложением или целой группой предложений… Во-вторых, у очень и очень многих слов, обладающих значением, нельзя найти соответствующего им понятия. Например, местоимения. «Я» — говорящий сейчас человек, взятый как целое, но немыслимо представить себе совокупность «я». Такая вольность допустима только в поэзии. Например, у Андрея Вознесенского: …Во мне, как в спектре, живут семь «я»… В-третьих, понятие — это то, что о данном предмете может сказать общество. А то, что я, отдельный человек, примысливаю к образу этого предмета, совершенно не обязательно совпадает с понятием. И даже значение слова, которое я использую, гораздо уже понятия. А главное, я, видя лопату, кошку, стол, не обязательно примысливаю к ним все те признаки, которые есть у соответствующих понятий. Значение возникает в моем сознании на основе тех признаков, которые закреплены в понятии, но это далеко не все признаки, — возможно, я знаю не все. Даже и значение слова, которое можно найти в словаре, отличается от понятия: это не то, что люди знают о предмете, а то, что им достаточно знать, чтобы правильно употреблять данное слово и правильно его понимать. Идут столетия, понятия исчезают, появляются новые, у старых меняется содержание. Сколько всяких приключений претерпело за последние сто лет понятие «свет»! А понятие «атом»? Но все эти изменения совершенно не обязательно отражаются в значении слова. «Мысль никогда не равна прямому значению слов», — говорил Л. С. Выготский. Но она и невозможна без слова. Понятия бывают различными. Тут и те, которыми мы пользуемся в повседневной жизни — вроде понятия «лопаты», и научные, строго определяемые, логически выдержанные — вроде понятия «галактика». Кстати, одно и то же понятие может выступать и как обыденное, житейское, и как научное. «Собака», например, и житейское понятие, определяемое простейшими способами — «домашнее животное, которое лает», и научное — вид Canis familiaris, принадлежащий семейству собак, отряду хищных, классу млекопитающих. Научные, как и все другие, понятия невозможны без словесной оболочки, без закрепления в языке, хотя в языке и не полностью отражаются их признаки. С одной стороны, мы в прямом смысле закрепляем в языке достижения нашего познания. С другой — мы можем узнавать новое о предметах, явлениях, процессах действительности благодаря языку, через его посредство. И вот оказывается, что язык способен выступать и как орудие познания. Мы можем при его помощи получать новые знания из уже имеющихся путем логических умозаключений. Всякое предложение отражает определенное отношение между предметами или событиями. Это может быть простейшее отношение, которое можно представить себе, не обращаясь к языку: например, «собака лает». Но может быть и сложное отношение, которое без помощи языка представить невозможно: «собака — животное». Говоря «собака — животное», мы совершенно не обязательно должны иметь перед глазами собаку. В том и сила (и еще одно важное отличие!) интеллектуального акта у человека, что он может быть не связан непосредственно с реальными предметами. Вы, вероятно, читали или слышали о том, как в середине века философы-схоласты пытались решить задачу — сколько чертей умещается на острие иглы? Они, несомненно, производили интеллектуальный акт, однако оперировали с такими «объектами» (чертями), которых не только не имели перед глазами, но и вообще никогда не видели и видеть не могли… Это совершенно не значит, что наше мышление вообще может протекать в отрыве от реальности. Время от времени мы вынуждены оглядываться и проверять, насколько наше отвлеченное, абстрактное мышление соответствует действительности. Если не проверять, могут произойти неприятные ошибки. Что же может быть средством проверки, или, как говорят в науке, критерием истинности мышления? Марксизм считает, что единственный такой критерий — практика. Но рассказ об этом увел бы нас слишком далеко, тем более что о критерии практики нам все равно еще придется говорить. Остановимся только на том, что проверка истинности вовсе не обязательно предполагает непосредственную трудовую деятельность или научный эксперимент: опыт практики учитывается нами и в самом процессе мышления, и формой такого учета являются логические законы мышления. Именно язык и представляет мышлению средства, необходимые для того, чтобы путем логического рассуждения, логических умозаключений проверить старые и получить новые знания. Леонтьев А. А. Мир человека и мир языка. — М., 1984. — С. 48–49. |
|
||
|
Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Другие сайты | Наверх |
||||
|
|
||||